






















-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
해당 자료는 4페이지 까지만 미리보기를 제공합니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1. 병렬 처리 개요
2. 컴퓨터 시스템 구조의 분류
3. 파이프라인 구조
4. 명령어 파이프라인
5. 파이프라인 CPU 설계 시 고려할 사항
6. 배열 프로세서(array processor) 구조
7. 다중 프로세서 시스템 구조
7.1 공유 메모리 시스템 구조
7.2 분산 메모리 시스템 구조
8. 데이터 풀로우(dataflow) 구조
8.1 데이터 풀로우 컴퓨터의 동작 원리
8.2 데이터 풀로우 컴퓨터의 구성
8.3 데이터 풀로우 컴퓨터의 프로그램
2. 컴퓨터 시스템 구조의 분류
3. 파이프라인 구조
4. 명령어 파이프라인
5. 파이프라인 CPU 설계 시 고려할 사항
6. 배열 프로세서(array processor) 구조
7. 다중 프로세서 시스템 구조
7.1 공유 메모리 시스템 구조
7.2 분산 메모리 시스템 구조
8. 데이터 풀로우(dataflow) 구조
8.1 데이터 풀로우 컴퓨터의 동작 원리
8.2 데이터 풀로우 컴퓨터의 구성
8.3 데이터 풀로우 컴퓨터의 프로그램
본문내용
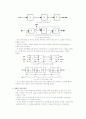
모리 SC : 시스템 제어기
IOP : 입출력 장치
계층 버스 구조를 가진 다중 프로세서 시스템의 구조
7.2 분산 메모리 시스템 구조
- 필요한 경우에 프로세서들이 네트워크를 통해서 정보를 메시지 형태로 주고 받는
메시지 전달 시스템
분산 메모리 구조
- 소결합 구조로서 각 프로세서들이 주 기억 장치를 공유하지 않고 자신의 기억 장치
를 별도로 가지고 있다.
- 다중 컴퓨터 시스템이라고 부르기도 한다.
- 각 프로세서들이 실행할 프로그램은 컴파일 단계에서부터 별도로 작성되어 각 지역
기억 장치에 적재되며, 프로세서들이 공유하는 데이터들만 서로 교환
- 프로세서들 사이에 통신량은 공유 메모리 시스템에 비해서 크게 줄어든다.
- 분산 메모리 시스템은 프로세서 사이에 메시지를 주고받으므로 통신을 수행하는 데
필요한 시간이 길어지지만 동시에 여러 쌍의 프로세서 사이에서 통신이 수행될 수
있다.
- 가장 널리 알려진 것은 하이퍼큐브 구조
하이퍼큐브의 기본 구조
- 하이퍼큐브는 기본적으로 "차원(dimension)"이라는 시스템 파라미터에 의해서 그
특성이 결정되며, 이 파라미터는 하이퍼큐브 내의 노드의 수와 각 노드들을 연결하는
통신 노드의 수를 결정한다.
8. 데이터 풀로우(dataflow) 구조
8.1 데이터 풀로우 컴퓨터의 동작 원리
- 프로그램 내의 모든 명령들을 그들이 수행하는 데이터들이 모두 준비되었을 때
수행시키는 구조
- 연산의 실행 순서를 연산에 필요한 데이터의 존재 여부로 결정하는 데이터 구동
(data driven) 구조
- 데이터의 흐름이 실행의 순서를 좌우하기 때문에 프로그램에는 동기화를 위한
표현이 불필요하고 프로그램 상의 모든 묵시적 병렬성이 모두 이용될 수 있다.
- 실행의 결과가 실행 순서나 속도에 관계없이 항상 일정하기 때문에 고도의 병렬성과
정확성을 얻을 수 있다.
- 데이터 풀로우 컴퓨터를 개발하는 입장에서는 프로그램에 명시된 병렬성으로 시스템
자원을 이용할 수 있도록 명시하여야 하고 또한 데이터의 존재 여부를 연산의 실행
순서로 치환하여야 한다.
*데이터 풀로우 그래프(dataflow graph)
- 방향이 있는 그래프
- 마디(node)와 가지(arc)로 구성
- 마디 : 연산을 표시
- 가지 : 데이터를 표시
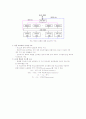
(예) 다음과 같은 계산을 수행하는 문제
데이터 플로우 그래프
- 그림에서 A, B, C, D 의 마디에 데이터가 발생하면 이들이 +, -, 등의 마디에 도착
한다. 그러면 연산이 행해지고 그 결과가 출력측의 가지에 나타나고, 이것이 다음
마디에 도달해서 연산이 행해지고 마지막으로 X 와 Y 를 얻게 됨.
- 마디는 입력측의 모든 가지에 데이터가 갖추어지면 연산을 행하고, 연산 결과를 출력
측의 가지에 송출
- 데이터 풀로우 그래프의 모든 마디가 병렬로, 상호간 독립적으로 동작해서 계산이
빠르게 행해 짐
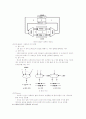
8.2 데이터 풀로우 컴퓨터의 구성
- 연산부는 n대의 프로세서 풀(pool)이며 이것이 분배망(distribution network)이라는
스위치 회로망을 통해서 기억부의 명령 셀에 연결
- 명령 셀은 데이터 풀로우 그래프의 마디에 대응해서 1 개씩 설치되어 있으며 여기에
는 연산의 종류, 명령 셀 번호, 오퍼런드의 번호 등이 미리 기록되어 있음
- 프로세서로부터 데이터가 도착하면 명령 셀의 오퍼런드부에 그 값이 기록
- 오퍼런드가 갖추어 지면 명령 셀은 조정망(arbitration network) 이라는 스위치
회로망을 통해서 그때 비어 있는 프로세서에 결합되어 연산이 행해짐
데이터 플로우 컴퓨터 개념도
*데이터 플로우 그래프의 마디 종류
가. 함수 마디
- 1개 또는 수 개의 오퍼런드에 연산을 행해서 1 개의 결과를 출력하는 마디
나. 선택 마디
- 2개의 통상적인 오퍼런드 외에 제어용의 오퍼런드를 입력하고 이 오퍼런드가 참인가
거짓인가에 의해서 두 오퍼런드 중에서 하나를 선택해서 출력하는 마디
다. 분기 마디
- 하나의 통상적인 오퍼런드와 하나의 제어 오퍼런드 및 2 개의 출력을 가지는 마디로
제어 오퍼런드가 참인가 거짓인가에 의해서 2 개의 출력 중 어느 한 쪽에 입력
오퍼런드를 내는 마디
각 종의 마디
*토큰(token)
- 마디에서 연산이 실행되어 출력 데이터가 발생했을 때 함께 만들어 지며, 데이터와
함께 마디로 전송됨
- 마디는 모든 입력 가지에 토큰이 갖추어지면 연산을 행하여 출력 가지에 출력
데이터와 토큰을 송출하고 동시에 입력가지의 토큰은 소멸하는 것으로 생각함.
8.3 데이터 풀로우 컴퓨터의 프로그램
- 데이터 풀로우 그래프 대신 각 마디의 연산식을 순서없이 배열해서 쓴 것으로 이들
연산식은 모두 대입문
예) 앞의 데이터 풀로우 그래프 그림에 대응하는 프로그램
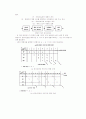
x := q/p ; y := r/p ;
p := s * t q := u - v ;
r := w - z ; s := a + b ;
t := a - b ; u := a * c ;
v := b * a ; w := a * d ;
z := b * c ;
- 단일 대입 언어(single - assignment language) 프로그램으로부터 데이터 풀로우
그래프를 일의적으로 만들 수 있고 따라서 데이터 풀로우 컴퓨터의 명령 셀을 만들
수 있다.
*문제점
- 프로그램의 병렬성을 검출해서 병렬 처리하기 위해서는 문제를 미세하게 분해해서
저레벨의 프로그램 언어로 기술해 주어야 하므로 매우 번거롭다.
- 하나의 마디에서 수행하는 연산 단위를 작게 하면 할수록 병렬성은 향상되지만 매우
많은 수의 명령 셀을 기억부와 연산부 사이에 순환시키기 위한 오버헤드가 막대하게
되어 오히려 처리 효율을 떨어뜨리게 된다.
- 데이터 풀로우 컴퓨터는 프로그램의 병렬성을 자동적으로 검출해서 병렬 처리하는
이상적인 병렬 컴퓨터이지만 그러기 위해서는 문제를 미세하게 분해해서 저레벨의
프로그램 언어로 기술해 주어야 하므로 매우 번거롭다. 그리고 하나의 마디에서
수행하는 연산 단위를 작게 하면 할수록 병렬성은 향상되지만 매우 많은 수의 명령
셀을 기억부와 연산부 사이에 순환시키기 위한 오버헤드가 막대하게 되어 오히려 처리
효율을 떨어뜨리게 되는 문제가 있다.
IOP : 입출력 장치
계층 버스 구조를 가진 다중 프로세서 시스템의 구조
7.2 분산 메모리 시스템 구조
- 필요한 경우에 프로세서들이 네트워크를 통해서 정보를 메시지 형태로 주고 받는
메시지 전달 시스템
분산 메모리 구조
- 소결합 구조로서 각 프로세서들이 주 기억 장치를 공유하지 않고 자신의 기억 장치
를 별도로 가지고 있다.
- 다중 컴퓨터 시스템이라고 부르기도 한다.
- 각 프로세서들이 실행할 프로그램은 컴파일 단계에서부터 별도로 작성되어 각 지역
기억 장치에 적재되며, 프로세서들이 공유하는 데이터들만 서로 교환
- 프로세서들 사이에 통신량은 공유 메모리 시스템에 비해서 크게 줄어든다.
- 분산 메모리 시스템은 프로세서 사이에 메시지를 주고받으므로 통신을 수행하는 데
필요한 시간이 길어지지만 동시에 여러 쌍의 프로세서 사이에서 통신이 수행될 수
있다.
- 가장 널리 알려진 것은 하이퍼큐브 구조
하이퍼큐브의 기본 구조
- 하이퍼큐브는 기본적으로 "차원(dimension)"이라는 시스템 파라미터에 의해서 그
특성이 결정되며, 이 파라미터는 하이퍼큐브 내의 노드의 수와 각 노드들을 연결하는
통신 노드의 수를 결정한다.
8. 데이터 풀로우(dataflow) 구조
8.1 데이터 풀로우 컴퓨터의 동작 원리
- 프로그램 내의 모든 명령들을 그들이 수행하는 데이터들이 모두 준비되었을 때
수행시키는 구조
- 연산의 실행 순서를 연산에 필요한 데이터의 존재 여부로 결정하는 데이터 구동
(data driven) 구조
- 데이터의 흐름이 실행의 순서를 좌우하기 때문에 프로그램에는 동기화를 위한
표현이 불필요하고 프로그램 상의 모든 묵시적 병렬성이 모두 이용될 수 있다.
- 실행의 결과가 실행 순서나 속도에 관계없이 항상 일정하기 때문에 고도의 병렬성과
정확성을 얻을 수 있다.
- 데이터 풀로우 컴퓨터를 개발하는 입장에서는 프로그램에 명시된 병렬성으로 시스템
자원을 이용할 수 있도록 명시하여야 하고 또한 데이터의 존재 여부를 연산의 실행
순서로 치환하여야 한다.
*데이터 풀로우 그래프(dataflow graph)
- 방향이 있는 그래프
- 마디(node)와 가지(arc)로 구성
- 마디 : 연산을 표시
- 가지 : 데이터를 표시
(예) 다음과 같은 계산을 수행하는 문제
데이터 플로우 그래프
- 그림에서 A, B, C, D 의 마디에 데이터가 발생하면 이들이 +, -, 등의 마디에 도착
한다. 그러면 연산이 행해지고 그 결과가 출력측의 가지에 나타나고, 이것이 다음
마디에 도달해서 연산이 행해지고 마지막으로 X 와 Y 를 얻게 됨.
- 마디는 입력측의 모든 가지에 데이터가 갖추어지면 연산을 행하고, 연산 결과를 출력
측의 가지에 송출
- 데이터 풀로우 그래프의 모든 마디가 병렬로, 상호간 독립적으로 동작해서 계산이
빠르게 행해 짐
8.2 데이터 풀로우 컴퓨터의 구성
- 연산부는 n대의 프로세서 풀(pool)이며 이것이 분배망(distribution network)이라는
스위치 회로망을 통해서 기억부의 명령 셀에 연결
- 명령 셀은 데이터 풀로우 그래프의 마디에 대응해서 1 개씩 설치되어 있으며 여기에
는 연산의 종류, 명령 셀 번호, 오퍼런드의 번호 등이 미리 기록되어 있음
- 프로세서로부터 데이터가 도착하면 명령 셀의 오퍼런드부에 그 값이 기록
- 오퍼런드가 갖추어 지면 명령 셀은 조정망(arbitration network) 이라는 스위치
회로망을 통해서 그때 비어 있는 프로세서에 결합되어 연산이 행해짐
데이터 플로우 컴퓨터 개념도
*데이터 플로우 그래프의 마디 종류
가. 함수 마디
- 1개 또는 수 개의 오퍼런드에 연산을 행해서 1 개의 결과를 출력하는 마디
나. 선택 마디
- 2개의 통상적인 오퍼런드 외에 제어용의 오퍼런드를 입력하고 이 오퍼런드가 참인가
거짓인가에 의해서 두 오퍼런드 중에서 하나를 선택해서 출력하는 마디
다. 분기 마디
- 하나의 통상적인 오퍼런드와 하나의 제어 오퍼런드 및 2 개의 출력을 가지는 마디로
제어 오퍼런드가 참인가 거짓인가에 의해서 2 개의 출력 중 어느 한 쪽에 입력
오퍼런드를 내는 마디
각 종의 마디
*토큰(token)
- 마디에서 연산이 실행되어 출력 데이터가 발생했을 때 함께 만들어 지며, 데이터와
함께 마디로 전송됨
- 마디는 모든 입력 가지에 토큰이 갖추어지면 연산을 행하여 출력 가지에 출력
데이터와 토큰을 송출하고 동시에 입력가지의 토큰은 소멸하는 것으로 생각함.
8.3 데이터 풀로우 컴퓨터의 프로그램
- 데이터 풀로우 그래프 대신 각 마디의 연산식을 순서없이 배열해서 쓴 것으로 이들
연산식은 모두 대입문
예) 앞의 데이터 풀로우 그래프 그림에 대응하는 프로그램
x := q/p ; y := r/p ;
p := s * t q := u - v ;
r := w - z ; s := a + b ;
t := a - b ; u := a * c ;
v := b * a ; w := a * d ;
z := b * c ;
- 단일 대입 언어(single - assignment language) 프로그램으로부터 데이터 풀로우
그래프를 일의적으로 만들 수 있고 따라서 데이터 풀로우 컴퓨터의 명령 셀을 만들
수 있다.
*문제점
- 프로그램의 병렬성을 검출해서 병렬 처리하기 위해서는 문제를 미세하게 분해해서
저레벨의 프로그램 언어로 기술해 주어야 하므로 매우 번거롭다.
- 하나의 마디에서 수행하는 연산 단위를 작게 하면 할수록 병렬성은 향상되지만 매우
많은 수의 명령 셀을 기억부와 연산부 사이에 순환시키기 위한 오버헤드가 막대하게
되어 오히려 처리 효율을 떨어뜨리게 된다.
- 데이터 풀로우 컴퓨터는 프로그램의 병렬성을 자동적으로 검출해서 병렬 처리하는
이상적인 병렬 컴퓨터이지만 그러기 위해서는 문제를 미세하게 분해해서 저레벨의
프로그램 언어로 기술해 주어야 하므로 매우 번거롭다. 그리고 하나의 마디에서
수행하는 연산 단위를 작게 하면 할수록 병렬성은 향상되지만 매우 많은 수의 명령
셀을 기억부와 연산부 사이에 순환시키기 위한 오버헤드가 막대하게 되어 오히려 처리
효율을 떨어뜨리게 되는 문제가 있다.
추천자료
- 가격2,000원
- 페이지수14페이지
- 등록일2007.11.18
- 저작시기2006.6
- 파일형식한글(hwp)
- 자료번호#437313

본 자료는 최근 2주간 다운받은 회원이 없습니다.



