


















-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
해당 자료는 2페이지 까지만 미리보기를 제공합니다.
2페이지 이후부터 다운로드 후 확인할 수 있습니다.
2페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
I. 조사 목적
II.주요 조사 내용
III. 조사 설계
1.표본설계 (Sample Design)
2.실사설계
3.조사방법 (Survey Method) 및 일시
IV. 자료 처리 및 분석
1.자료 처리(Data Processing)
2.분석(Analysis)
(1) 고객만족도(CSI) 지수 산출방법
1) 척도 (Scale)
2) 만족도 산출방법
① 항목만족도
② 차원만족도
③ 요소별만족도
④ 체감만족도
⑤ 종합만족도지수
3) 중요도 (가중치) 산출 방법
① 항목중요도
② 차원중요도
(2) CSI 평가체계
(3) CS Portfolio 분석
(4) 응답자 특성별 분석
(5) 기타의견 분석
(6) 분산분석(ANOVA)
II.주요 조사 내용
III. 조사 설계
1.표본설계 (Sample Design)
2.실사설계
3.조사방법 (Survey Method) 및 일시
IV. 자료 처리 및 분석
1.자료 처리(Data Processing)
2.분석(Analysis)
(1) 고객만족도(CSI) 지수 산출방법
1) 척도 (Scale)
2) 만족도 산출방법
① 항목만족도
② 차원만족도
③ 요소별만족도
④ 체감만족도
⑤ 종합만족도지수
3) 중요도 (가중치) 산출 방법
① 항목중요도
② 차원중요도
(2) CSI 평가체계
(3) CS Portfolio 분석
(4) 응답자 특성별 분석
(5) 기타의견 분석
(6) 분산분석(ANOVA)
본문내용
중치 = (0.1 + 0.25) ÷ 2 로 구해짐.
항목중요도 = (항목별 응답비율 + 무작위 선택 비율) /2
② 차원중요도 : 해당차원이 종합만족도 지수에 영향을 미치는 정도를 말함.
(가중치) 평가차원에 가장 중요하다고 응답된 비율
(Frequency)과 무작위 선택비율 (Random Choice Ratio)의
중간값을 적용.
예를 들어 평가차원이 세 개 차원이고 차원1차원2차원3
중 가장 중요하다고 응답한 비율이 각각 45%35%20%
라고 가정하면, 평가차원1의 가중치는 (0.45 + 0.33) ÷ 2가 됨.
첫 번째의 0.45는 45% 응답비율(Frequency)을 의미하고, 0.33은 평가차원 셋 중 하나가 무작위로 선택되는 비율(Random Choice
Ratio)을 말함. 2로 나누는 이유는 세 개 차원 중 하나를
선택한 45%의 응답자가 생각하는 중요도에는 다양한 차이가
존재할 수 있기 때문에 이를 중간값으로 처리하기 위한 것임.
즉 (선택도수비율 + 무작위선택비율) ÷ 2의 식이 형성됨.
평가차원2의 가중치 = (0.35 + 0.33) ÷ 2
평가차원3의 가중치 = (0.2 + 0.33) ÷ 2 로 구해질 수 있음.
차원중요도 = (차원별 응답비율 + 무작위 선택 비율) /2
(2) CSI 평가체계
(3) CS Portfolio 분석
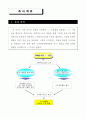
각 만족도와 중요도를 고려하여 자원의 효율적 배분과 관련된 전략적 시사점을 도출하기 위해 4개 영역으로 나누고, 각 세부항목의 영역내 위치를 파악해 영역별로 의미를 해석함.
한가지 주지할 사실은 만족도제고나 소극적 관리에 속하는 서비스 차원이나 항목이라고 해서 반드시 개선의 노력을 줄이거나 관심을 덜 기울일 필요가 있는 사항이라 할 수 없음.
단지 만족한 수준이라 응답자의 관심이 덜가는 서비스 사항이라고 해석할 수 있으며 이러한 사항들의 만족도가 하락하는 경우 중요도는 올라가는 현상이 발생할 수 있으므로 적어도 현재 수준의 만족도 유지가 필요함.
〈 Portfolio Map 〉
[ Portfolio Map ]
중요도
A 영역 :만족도↓
중점개선요망중요도↑
C 영역 : 만족도↑
유지/중요도↑
관리지속
중요도평균
B 영역 :만족도↓
만족도 제고중요도↓
D 영역 : 만족도↑
소극적 관리중요도↓
만족도 평균
만족도
☞ 중요도 및 만족도 축의 설정
만족도(평균)를 X축, 각 중요도 평균을 Y축으로 하여 A, B, C, D의 4개 분면을
구성함.
[ 의 미 ]
영역명칭
의 미
A 영역 : 중점개선요망
즉각적 개선 필요
B 영역 : 만족도 제고
우선순위가 상대적으로 낮은 영역
C 영역 : 유지/관리 지속
고객만족을 높이기 위해
지속적인 노력이 요청됨.
D 영역 : 소극적 관리
현재 수준 유지나 불가피 할 경우
다른 영역으로 자원을 배분
(4) 응답자 특성별 분석
만족도 수준은 응답자의 특성에 따라서 달라질 수 있는데, 이를 분석함으로써 종합 만족도 수준을 높이기 위해 어떤 집단을 표적집단(Target)으로 해야 할 지를 파악해 낼 수 있음.
(5) 기타의견 분석
지하철 서비스에 대한 시민 만족도를 평가함에 있어 개방형 질문에 의한 기타의견 분석도 상당히 중요한 역할을 하는데, 이를 통해 기존 설문 구성체계로 파악되지 않는 심층적 정보들을 획득할 수 있음.
(6) 분산분석(ANOVA)
지하철 서비스 고객만족도 조사시, 연령, 교육수준, 조사장소 등 변수별로 조사 대상을 나누어
평가를 받게 되는데, 이때 한 변수 내에 있는 각 집단의 만족도 차이가 통계적으로 유의미
한지를 알아보기 위해 분산분석을 사용함. F값은 집단 간의 차이가 있음을 나타내는 값이고,
P값은 F값이 통계적으로 유의미한지를 나타내는 값임.
항목중요도 = (항목별 응답비율 + 무작위 선택 비율) /2
② 차원중요도 : 해당차원이 종합만족도 지수에 영향을 미치는 정도를 말함.
(가중치) 평가차원에 가장 중요하다고 응답된 비율
(Frequency)과 무작위 선택비율 (Random Choice Ratio)의
중간값을 적용.
예를 들어 평가차원이 세 개 차원이고 차원1차원2차원3
중 가장 중요하다고 응답한 비율이 각각 45%35%20%
라고 가정하면, 평가차원1의 가중치는 (0.45 + 0.33) ÷ 2가 됨.
첫 번째의 0.45는 45% 응답비율(Frequency)을 의미하고, 0.33은 평가차원 셋 중 하나가 무작위로 선택되는 비율(Random Choice
Ratio)을 말함. 2로 나누는 이유는 세 개 차원 중 하나를
선택한 45%의 응답자가 생각하는 중요도에는 다양한 차이가
존재할 수 있기 때문에 이를 중간값으로 처리하기 위한 것임.
즉 (선택도수비율 + 무작위선택비율) ÷ 2의 식이 형성됨.
평가차원2의 가중치 = (0.35 + 0.33) ÷ 2
평가차원3의 가중치 = (0.2 + 0.33) ÷ 2 로 구해질 수 있음.
차원중요도 = (차원별 응답비율 + 무작위 선택 비율) /2
(2) CSI 평가체계
(3) CS Portfolio 분석
각 만족도와 중요도를 고려하여 자원의 효율적 배분과 관련된 전략적 시사점을 도출하기 위해 4개 영역으로 나누고, 각 세부항목의 영역내 위치를 파악해 영역별로 의미를 해석함.
한가지 주지할 사실은 만족도제고나 소극적 관리에 속하는 서비스 차원이나 항목이라고 해서 반드시 개선의 노력을 줄이거나 관심을 덜 기울일 필요가 있는 사항이라 할 수 없음.
단지 만족한 수준이라 응답자의 관심이 덜가는 서비스 사항이라고 해석할 수 있으며 이러한 사항들의 만족도가 하락하는 경우 중요도는 올라가는 현상이 발생할 수 있으므로 적어도 현재 수준의 만족도 유지가 필요함.
〈 Portfolio Map 〉
[ Portfolio Map ]
중요도
A 영역 :만족도↓
중점개선요망중요도↑
C 영역 : 만족도↑
유지/중요도↑
관리지속
중요도평균
B 영역 :만족도↓
만족도 제고중요도↓
D 영역 : 만족도↑
소극적 관리중요도↓
만족도 평균
만족도
☞ 중요도 및 만족도 축의 설정
만족도(평균)를 X축, 각 중요도 평균을 Y축으로 하여 A, B, C, D의 4개 분면을
구성함.
[ 의 미 ]
영역명칭
의 미
A 영역 : 중점개선요망
즉각적 개선 필요
B 영역 : 만족도 제고
우선순위가 상대적으로 낮은 영역
C 영역 : 유지/관리 지속
고객만족을 높이기 위해
지속적인 노력이 요청됨.
D 영역 : 소극적 관리
현재 수준 유지나 불가피 할 경우
다른 영역으로 자원을 배분
(4) 응답자 특성별 분석
만족도 수준은 응답자의 특성에 따라서 달라질 수 있는데, 이를 분석함으로써 종합 만족도 수준을 높이기 위해 어떤 집단을 표적집단(Target)으로 해야 할 지를 파악해 낼 수 있음.
(5) 기타의견 분석
지하철 서비스에 대한 시민 만족도를 평가함에 있어 개방형 질문에 의한 기타의견 분석도 상당히 중요한 역할을 하는데, 이를 통해 기존 설문 구성체계로 파악되지 않는 심층적 정보들을 획득할 수 있음.
(6) 분산분석(ANOVA)
지하철 서비스 고객만족도 조사시, 연령, 교육수준, 조사장소 등 변수별로 조사 대상을 나누어
평가를 받게 되는데, 이때 한 변수 내에 있는 각 집단의 만족도 차이가 통계적으로 유의미
한지를 알아보기 위해 분산분석을 사용함. F값은 집단 간의 차이가 있음을 나타내는 값이고,
P값은 F값이 통계적으로 유의미한지를 나타내는 값임.
추천자료
- 가격1,900원
- 페이지수8페이지
- 등록일2008.01.01
- 저작시기2008.1
- 파일형식한글(hwp)
- 자료번호#445393

본 자료는 최근 2주간 다운받은 회원이 없습니다.



