

































































-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
해당 자료는 10페이지 까지만 미리보기를 제공합니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1. 연습문제 8장(268페이지) 2번, 3번
2. 연습문제 9장(284페이지) 2번, 3번
3. 연습문제 10장(300페이지) 1번, 2번
4. 연습문제 11장(320페이지) 1번, 2번
2. 연습문제 9장(284페이지) 2번, 3번
3. 연습문제 10장(300페이지) 1번, 2번
4. 연습문제 11장(320페이지) 1번, 2번
본문내용
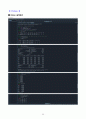
ing)
summary(downloading_fit)
TukeyHSD(downloading_fit)
tukey.test = TukeyHSD(downloading_fit)
plot(tukey.test)
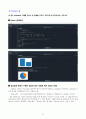
【 Python 】
(1) 세 가지 시간대별로 다운로드에 걸리는 시간이 다른지 분석하시오.
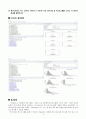
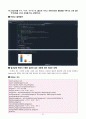
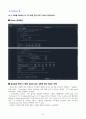
Python 출력화면
결과설명 (R에서 수행한 결과와 같은 내용에 대한 언급은 생략)
시간대에 따라 파일을 다운로드하는 데 걸리는 시간의 평균에 차이가 있는지를 알아보기 위해서는 『pandas』모듈 외에도 『researchpy』모듈이 필요하다. 이를 위해 먼저 도스(Dos) 창에서 『C:\\> pip install researchpy』명령을 실행하여 설치한다.
『statsmodels』모듈의 『ols』함수를 사용하여 분산분석 모형을 적합하였다. coef의 값을 보면, 「Intercept=113.375, [T.Evening (5 875PM)]=159.9375, [T.Late Night (12 AM)]=79.5」가 나오는 것이 확인된다. Time_of_Day 중 Early (7AM)의 평균 113.375를 기준으로 하고, (273.3125-113.375, 193.0625-113.375) = (159.9375, 79.6875), 즉 Time_of_Day 중 Early (7AM) 그룹과의 평균차이를 의미한다. 분산분석 결과 aov_fit는 『sm.stats.anova_lm』함수를 이용하여 구할 수 있다.
분산분석 결과에 관한 설명은 R에서 수행한 결과와 동일하므로 생략한다.
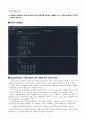
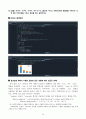
Python 코드
import pandas as pd
import researchpy as rp
downloading = pd.read_csv(\"C:/rpython/downloading.csv\")
downloading.head(3)
rp.summary_cont(downloading[\'Time_Sec\'].groupby(downloading[\'Time_of_Day\']))
import statsmodels.api as sm
from statsmodels.formula.api import ols
fit = ols(\'downloading.Time_Sec ~ C(downloading.Time_of_Day)\', data=downloading).fit()
fit.summary()
aov_fit = sm.stats.anova_lm(fit, typ=2)
aov_fit
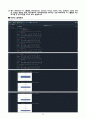
(2) 각 시간대별로 차이가 있는지 다중비교를 통해 분석하시오.
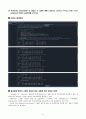
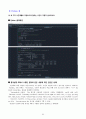
Python 출력화면
결과설명(R에서 수행한 결과와 같은 내용에 대한 언급은 생략)
위의 화면은 『ols』함수를 사용하여 분산분석 모형을 적합하고,『MultiComparison』, 『tukeyhsd』함수를 이용하여 Tukey의 다중비교 방법을 수행하는 절차를 보여준다.
group1과 group2의 평균 및 평균차이 신뢰구간을 제시하여 주었으며, 유의수준 0.05에서 통계적으로 유의미한 차이가 있으면 True가 표시되고, 반대의 경우 False가 표시된다.
분산분석 및 다중비교 수행 결과에 관한 설명은 R에서 수행한 결과와 동일하므로 생략한다.
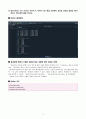
Python 코드
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.multicomp import pairwise_tukeyhsd
from statsmodels.stats.multicomp import MultiComparison
downloading = pd.read_csv(\"C:/rpython/downloading.csv\")
fit = ols(\'downloading.Time_Sec ~ C(downloading.Time_of_Day)\', data=downloading).fit()
mc = MultiComparison(downloading[\'Time_Sec\'], downloading[\'Time_of_Day\'])
mc_tukey = mc.tukeyhsd()
print(mc_tukey)
<참고문헌>
심송용, 이윤동, 김성수, 「파이썬과 R」, 한국방송통신대학교 출판문화원, 2020.
장영재, 최상범, 한승봉, 「R컴퓨팅」, 한국방송통신대학교 출판문화원, 2020.
이태림, 장영재, 이기재, 이긍희, 「통계학개론」, 한국방송통신대학교 출판문화원, 2015.
심송용, 이윤동, 이은경, 김성수, 「고급R활용」, 한국방송통신대학교 출판문화원, 2015.
김성수, 김현중, 정성석, 이용구, 「다변량분석」, 한국방송통신대학교 출판문화원, 2014.
윤인성,「혼자 공부하는 파이썬」, 한빛미디어, 2019.
[python] 파이썬 결측치 처리https://freedata.tistory.com/61
WorkingWithPython, pandas로 결측치 다루기https://workingwithpython.com/howtohandlemissingvaluewithpython/
[빅데이터 통계 R 프로그램(8)] 데이터분석 시작! (05) 연령대와 월급 https://goodthought.tistory.com/57
R 프로그래밍, 상호작용이 있는 다중회귀분석https://m.blog.naver.com/PostView.nhn?blogId=ilustion&logNo=220284437544&proxyReferer=https:%2F%2Fwww.google.com%2F
Kaggle에서 파이썬으로 데이터분석 시작하기, 02-데이터분석 라이브러리, 01-03-01 Data manipulationhttps://wikidocs.net/75113
#파이썬. 상관관계분석(피어슨 상관계수)https://m.blog.naver.com/PostView.nhn?blogId=nonamed0000&logNo=220908895209&proxyReferer=https:%2F%2Fwww.google.com%2F
[회귀분석] 6. 변수선택법(Variable Selection) with Pythonhttps://zephyrus1111.tistory.com/65
summary(downloading_fit)
TukeyHSD(downloading_fit)
tukey.test = TukeyHSD(downloading_fit)
plot(tukey.test)
【 Python 】
(1) 세 가지 시간대별로 다운로드에 걸리는 시간이 다른지 분석하시오.
Python 출력화면
결과설명 (R에서 수행한 결과와 같은 내용에 대한 언급은 생략)
시간대에 따라 파일을 다운로드하는 데 걸리는 시간의 평균에 차이가 있는지를 알아보기 위해서는 『pandas』모듈 외에도 『researchpy』모듈이 필요하다. 이를 위해 먼저 도스(Dos) 창에서 『C:\\> pip install researchpy』명령을 실행하여 설치한다.
『statsmodels』모듈의 『ols』함수를 사용하여 분산분석 모형을 적합하였다. coef의 값을 보면, 「Intercept=113.375, [T.Evening (5 875PM)]=159.9375, [T.Late Night (12 AM)]=79.5」가 나오는 것이 확인된다. Time_of_Day 중 Early (7AM)의 평균 113.375를 기준으로 하고, (273.3125-113.375, 193.0625-113.375) = (159.9375, 79.6875), 즉 Time_of_Day 중 Early (7AM) 그룹과의 평균차이를 의미한다. 분산분석 결과 aov_fit는 『sm.stats.anova_lm』함수를 이용하여 구할 수 있다.
분산분석 결과에 관한 설명은 R에서 수행한 결과와 동일하므로 생략한다.
Python 코드
import pandas as pd
import researchpy as rp
downloading = pd.read_csv(\"C:/rpython/downloading.csv\")
downloading.head(3)
rp.summary_cont(downloading[\'Time_Sec\'].groupby(downloading[\'Time_of_Day\']))
import statsmodels.api as sm
from statsmodels.formula.api import ols
fit = ols(\'downloading.Time_Sec ~ C(downloading.Time_of_Day)\', data=downloading).fit()
fit.summary()
aov_fit = sm.stats.anova_lm(fit, typ=2)
aov_fit
(2) 각 시간대별로 차이가 있는지 다중비교를 통해 분석하시오.
Python 출력화면
결과설명(R에서 수행한 결과와 같은 내용에 대한 언급은 생략)
위의 화면은 『ols』함수를 사용하여 분산분석 모형을 적합하고,『MultiComparison』, 『tukeyhsd』함수를 이용하여 Tukey의 다중비교 방법을 수행하는 절차를 보여준다.
group1과 group2의 평균 및 평균차이 신뢰구간을 제시하여 주었으며, 유의수준 0.05에서 통계적으로 유의미한 차이가 있으면 True가 표시되고, 반대의 경우 False가 표시된다.
분산분석 및 다중비교 수행 결과에 관한 설명은 R에서 수행한 결과와 동일하므로 생략한다.
Python 코드
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.multicomp import pairwise_tukeyhsd
from statsmodels.stats.multicomp import MultiComparison
downloading = pd.read_csv(\"C:/rpython/downloading.csv\")
fit = ols(\'downloading.Time_Sec ~ C(downloading.Time_of_Day)\', data=downloading).fit()
mc = MultiComparison(downloading[\'Time_Sec\'], downloading[\'Time_of_Day\'])
mc_tukey = mc.tukeyhsd()
print(mc_tukey)
<참고문헌>
심송용, 이윤동, 김성수, 「파이썬과 R」, 한국방송통신대학교 출판문화원, 2020.
장영재, 최상범, 한승봉, 「R컴퓨팅」, 한국방송통신대학교 출판문화원, 2020.
이태림, 장영재, 이기재, 이긍희, 「통계학개론」, 한국방송통신대학교 출판문화원, 2015.
심송용, 이윤동, 이은경, 김성수, 「고급R활용」, 한국방송통신대학교 출판문화원, 2015.
김성수, 김현중, 정성석, 이용구, 「다변량분석」, 한국방송통신대학교 출판문화원, 2014.
윤인성,「혼자 공부하는 파이썬」, 한빛미디어, 2019.
[python] 파이썬 결측치 처리https://freedata.tistory.com/61
WorkingWithPython, pandas로 결측치 다루기https://workingwithpython.com/howtohandlemissingvaluewithpython/
[빅데이터 통계 R 프로그램(8)] 데이터분석 시작! (05) 연령대와 월급 https://goodthought.tistory.com/57
R 프로그래밍, 상호작용이 있는 다중회귀분석https://m.blog.naver.com/PostView.nhn?blogId=ilustion&logNo=220284437544&proxyReferer=https:%2F%2Fwww.google.com%2F
Kaggle에서 파이썬으로 데이터분석 시작하기, 02-데이터분석 라이브러리, 01-03-01 Data manipulationhttps://wikidocs.net/75113
#파이썬. 상관관계분석(피어슨 상관계수)https://m.blog.naver.com/PostView.nhn?blogId=nonamed0000&logNo=220908895209&proxyReferer=https:%2F%2Fwww.google.com%2F
[회귀분석] 6. 변수선택법(Variable Selection) with Pythonhttps://zephyrus1111.tistory.com/65
추천자료
 인사서지(교육학관련분야 2차 3차 자료에 대한 해제)
인사서지(교육학관련분야 2차 3차 자료에 대한 해제)- 한국방송통신대학(방통대) 평생교육원의 연혁, 한국방송통신대학(방통대) 평생교육원의 교육...
- 한국방송통신대학(방통대) 평생교육원의 설립취지, 한국방송통신대학(방통대) 평생교육원의 ...
- [푸드마케팅 공통] 1 식품 등의 표시기준의 목적과 중요성을 소비자와 생산자의 입장으로 구...
- [푸드마케팅 공통] 1 식품 등의 표시기준의 목적과 중요성을 소비자와 생산자의 입장으로 구...
- 지역사회간호학 기말시험 온라인과제] I.지역사회간호사업을 위한 4가지 우선순위성정기법(PA...
- 교육심리학 2020년 방송대 기말] 행동주의학습이론 인지주의학습이론 사회학습이론 인본주의...
- <30점 만점> 2020학년도 파이썬과R 출석수업대체과제 한국방송통신대학교 통계데이터과학과
- [간호연구] 2021년, 1. 양적 연구방법은 간호학 분야에서 널리 사용되고 있다. 양적 연구의 ...
- 가격9,000원
- 페이지수73페이지
- 등록일2021.03.08
- 저작시기2020.11
- 파일형식한글(hwp)
- 자료번호#1146000

본 자료는 최근 2주간 다운받은 회원이 없습니다.



소개글