



























-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
해당 자료는 5페이지 까지만 미리보기를 제공합니다.
5페이지 이후부터 다운로드 후 확인할 수 있습니다.
5페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
R과 파이썬을 각각 이용하여 작성하시오.
1. 교재 연습문제 1장 3번, 4번 (12점)
1) 자유도가 5인 t-분포를 따르는 난수 100개를 만들어 분석하고자 한다. R과 파이썬을 이용하여 다음에 답하시오.
2) 다음은 R에 내장된 “longley" 데이터이다.
2. 교재 연습문제 2장 3번 (8점)
다음은 어느 도시의 14개 지역에 대한 사회조사자료이다. 이 자료를 이용하여 다음과 같이 주성분분석을 실시하시오.
3. 교재 연습문제 4장 3번 (1)-(3) (10점)
세계의 46개 주요 도시에 대한 물가와 소득에 관한 데이터를 아래와 같이 수집하였다(1991년 기준). R과 파이썬을 각각 이용하여 46개 도시에 대한 군집분석을 다음과 같이 실시하시오.
4. 참고문헌
1. 교재 연습문제 1장 3번, 4번 (12점)
1) 자유도가 5인 t-분포를 따르는 난수 100개를 만들어 분석하고자 한다. R과 파이썬을 이용하여 다음에 답하시오.
2) 다음은 R에 내장된 “longley" 데이터이다.
2. 교재 연습문제 2장 3번 (8점)
다음은 어느 도시의 14개 지역에 대한 사회조사자료이다. 이 자료를 이용하여 다음과 같이 주성분분석을 실시하시오.
3. 교재 연습문제 4장 3번 (1)-(3) (10점)
세계의 46개 주요 도시에 대한 물가와 소득에 관한 데이터를 아래와 같이 수집하였다(1991년 기준). R과 파이썬을 각각 이용하여 46개 도시에 대한 군집분석을 다음과 같이 실시하시오.
4. 참고문헌
본문내용
riance_ratio_.cumsum()
위 결과는 R에서의 누적 정보량과 일치한다.
3. 교재 연습문제 4장 3번 (1)-(3) (10점)
세계의 46개 주요 도시에 대한 물가와 소득에 관한 데이터를 아래와 같이 수집하였다(1991년 기준). R과 파이썬을 각각 이용하여 46개 도시에 대한 군집분석을 다음과 같이 실시하시오.
도시
평균노동시간
물가(Zurihi=100)
소득(Zurihi=100)
Amsterdam
1714
65.6
49
Athens
1792
53.8
30.4
Bogota
2152
37.9
11.5
Bombay
2052
30.3
5.3
Brussels
1708
73.8
50.5
Buenos Aires
1971
56.1
12.5
Caracas
2041
61
10.9
Chicago
1924
73.9
61.9
Copenhagen
1717
91.3
62.9
Dublin
1759
76
41.4
Dusseldorf
1693
78.5
60.2
Frankfurt
1650
74.5
60.4
Geneva
1880
95.9
90.3
Helsinki
1667
113.6
66.6
Hong Kong
2375
63.8
27.8
Houston
1978
71.9
46.3
Johannesburg
1945
51.1
24
Kuala Lumpur
2167
43.5
9.9
Lagos
1786
45.2
2.7
Lisbon
1742
56.2
18.8
London
1737
84.2
46.2
Los Angeles
2068
79.8
65.2
Luxembourg
1768
71.1
71.1
Madrid
1710
93.8
50
Manila
2268
40
4
Mexico City
1944
49.8
5.7
Milan
1773
82
53.3
Montreal
1827
72.7
56.3
Nairobi
1958
45
5.8
New York
1942
83.3
65.8
Nicosia
1825
47.9
28.3
Oslo
1583
115.5
63.7
Panama
2078
49.2
13.8
Paris
1744
81.6
45.9
Rio de Janeiro
1749
46.3
10.5
Sao Paulo
1856
48.9
11.1
Seoul
1842
58.3
32.7
Singpore
2042
64.4
16.1
Stockholm
1805
111.3
39.2
Sydney
1668
70.8
52.1
Taipei
2145
84.3
34.5
Tel Aviv
2015
67.3
27
Tokyo
1880
115
68
Toronto
1888
70.2
58.2
Vienna
1780
78
51.3
(1) 각 변수로 관찰값들을 표준화하시오.
①R
library(readxl)
data = read_excel(\"C:/Users/hulla/Desktop/data.xlsx\")
zdata = scale(data[c(\"평균노동시간\", \"물가\", \"소득\")]) # 표준화
round(apply(zdata, 2, mean),3)
round(apply(zdata, 2, sd), 3)
②파이썬
import pandas as pd
from sklearn.preprocessing import StandardScaler
data = pd.read_excel(\"C:/Users/hulla/Desktop/data.xlsx\", index_col=0)
zdata = StandardScaler().fit_transform(data) # 표준화
(2) 최장연결법을 이용하여 도시들을 군집화하고 덴드로그램으로 표현하시오. 몇 개의 군집이 적절하다고 판단되는지 설명하시오.
①R
zdata_euc = dist(zdata) # 거리행렬
hc_c = hclust(zdata_euc, method=\"complete\")
hc_c
plot(hc_c, hang=-1)
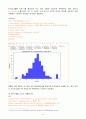
교재(p142)에서는 덴드로그램에서 거리측도의 값이 큰 변화를 보이는 위치에서 군집의 수를 결정한다고 설명되어 있다. 즉, 랜드로그램에서 서로 연결된 짧은 거리의 관찰치들을 하나의 군집이라 생각하고 이러한 군집의 수를 최종적인 군집의 수로 결정하는 방식이다. 이 방법에 따라 덴도로그램에서 거리가 2 전후에 해당하는 군집을 선택하여 최적의 군집 수를 4개로 결정했다. 단, 4개 중 파란색 군집은 2가 되지 않는 군집이다.
②파이썬
import matplotlib.pyplot as plt
import scipy.cluster.hierarchy as sch
clink = sch.linkage(zdata, \'complete\')
sch.dendrogram(clink, leaf_rotation=80, leaf_font_size=1, labels=data.index)
plt.show()
R의 덴드로그램과 동일한 형상이므로 덴드로그램에서 거리가 2 전후인 군집을 선택하여 최적의 군집 수로 하여 4개로 결정했다.
(3) K-평균 군집분석방법을 이용하여 4개 군집에 대한 군집분석을 실시하시오.
①R
# K-Means 알고리즘은 초기 중심점을 무작위로 선택하므로 결과는 실행할 때마다 달라지
# 므로 각 군집별 평균을 이용하여 군집별 특성을 기술할 때 유의해야 함.
kmc = kmeans(zdata, centers=4)
kmc
# 각 군집별 색깔 지정하기(1:red ~ 6:black)
colors <- c(\"red\", \"green\", \"orange\", \"black\")
col_by_cluster <- colors[kmc$cluster]
# k-평균 군집 데이터를 이용한 산점도행렬(cluster별로 색깔 지정)
pairs(zdata, col = col_by_cluster, pch = 16, cex.labels = 1.5)
②파이썬
from sklearn.cluster import KMeans
kmc = KMeans(n_clusters=4, random_state=0)
kmc.fit(zdata)
# 군집 중심 알기
kmc.cluster_centers_
# 소속 군집 알기
kmc.labels_
4. 참고문헌
김성수·김현중·정성석·이용구(2022), 다변량분석, 방송통신대학교출판문화원.
박서영·이기재·이긍희·장영재(2022), 통계학개론, 한국방송통신대학교출판문화원.
위 결과는 R에서의 누적 정보량과 일치한다.
3. 교재 연습문제 4장 3번 (1)-(3) (10점)
세계의 46개 주요 도시에 대한 물가와 소득에 관한 데이터를 아래와 같이 수집하였다(1991년 기준). R과 파이썬을 각각 이용하여 46개 도시에 대한 군집분석을 다음과 같이 실시하시오.
도시
평균노동시간
물가(Zurihi=100)
소득(Zurihi=100)
Amsterdam
1714
65.6
49
Athens
1792
53.8
30.4
Bogota
2152
37.9
11.5
Bombay
2052
30.3
5.3
Brussels
1708
73.8
50.5
Buenos Aires
1971
56.1
12.5
Caracas
2041
61
10.9
Chicago
1924
73.9
61.9
Copenhagen
1717
91.3
62.9
Dublin
1759
76
41.4
Dusseldorf
1693
78.5
60.2
Frankfurt
1650
74.5
60.4
Geneva
1880
95.9
90.3
Helsinki
1667
113.6
66.6
Hong Kong
2375
63.8
27.8
Houston
1978
71.9
46.3
Johannesburg
1945
51.1
24
Kuala Lumpur
2167
43.5
9.9
Lagos
1786
45.2
2.7
Lisbon
1742
56.2
18.8
London
1737
84.2
46.2
Los Angeles
2068
79.8
65.2
Luxembourg
1768
71.1
71.1
Madrid
1710
93.8
50
Manila
2268
40
4
Mexico City
1944
49.8
5.7
Milan
1773
82
53.3
Montreal
1827
72.7
56.3
Nairobi
1958
45
5.8
New York
1942
83.3
65.8
Nicosia
1825
47.9
28.3
Oslo
1583
115.5
63.7
Panama
2078
49.2
13.8
Paris
1744
81.6
45.9
Rio de Janeiro
1749
46.3
10.5
Sao Paulo
1856
48.9
11.1
Seoul
1842
58.3
32.7
Singpore
2042
64.4
16.1
Stockholm
1805
111.3
39.2
Sydney
1668
70.8
52.1
Taipei
2145
84.3
34.5
Tel Aviv
2015
67.3
27
Tokyo
1880
115
68
Toronto
1888
70.2
58.2
Vienna
1780
78
51.3
(1) 각 변수로 관찰값들을 표준화하시오.
①R
library(readxl)
data = read_excel(\"C:/Users/hulla/Desktop/data.xlsx\")
zdata = scale(data[c(\"평균노동시간\", \"물가\", \"소득\")]) # 표준화
round(apply(zdata, 2, mean),3)
round(apply(zdata, 2, sd), 3)
②파이썬
import pandas as pd
from sklearn.preprocessing import StandardScaler
data = pd.read_excel(\"C:/Users/hulla/Desktop/data.xlsx\", index_col=0)
zdata = StandardScaler().fit_transform(data) # 표준화
(2) 최장연결법을 이용하여 도시들을 군집화하고 덴드로그램으로 표현하시오. 몇 개의 군집이 적절하다고 판단되는지 설명하시오.
①R
zdata_euc = dist(zdata) # 거리행렬
hc_c = hclust(zdata_euc, method=\"complete\")
hc_c
plot(hc_c, hang=-1)
교재(p142)에서는 덴드로그램에서 거리측도의 값이 큰 변화를 보이는 위치에서 군집의 수를 결정한다고 설명되어 있다. 즉, 랜드로그램에서 서로 연결된 짧은 거리의 관찰치들을 하나의 군집이라 생각하고 이러한 군집의 수를 최종적인 군집의 수로 결정하는 방식이다. 이 방법에 따라 덴도로그램에서 거리가 2 전후에 해당하는 군집을 선택하여 최적의 군집 수를 4개로 결정했다. 단, 4개 중 파란색 군집은 2가 되지 않는 군집이다.
②파이썬
import matplotlib.pyplot as plt
import scipy.cluster.hierarchy as sch
clink = sch.linkage(zdata, \'complete\')
sch.dendrogram(clink, leaf_rotation=80, leaf_font_size=1, labels=data.index)
plt.show()
R의 덴드로그램과 동일한 형상이므로 덴드로그램에서 거리가 2 전후인 군집을 선택하여 최적의 군집 수로 하여 4개로 결정했다.
(3) K-평균 군집분석방법을 이용하여 4개 군집에 대한 군집분석을 실시하시오.
①R
# K-Means 알고리즘은 초기 중심점을 무작위로 선택하므로 결과는 실행할 때마다 달라지
# 므로 각 군집별 평균을 이용하여 군집별 특성을 기술할 때 유의해야 함.
kmc = kmeans(zdata, centers=4)
kmc
# 각 군집별 색깔 지정하기(1:red ~ 6:black)
colors <- c(\"red\", \"green\", \"orange\", \"black\")
col_by_cluster <- colors[kmc$cluster]
# k-평균 군집 데이터를 이용한 산점도행렬(cluster별로 색깔 지정)
pairs(zdata, col = col_by_cluster, pch = 16, cex.labels = 1.5)
②파이썬
from sklearn.cluster import KMeans
kmc = KMeans(n_clusters=4, random_state=0)
kmc.fit(zdata)
# 군집 중심 알기
kmc.cluster_centers_
# 소속 군집 알기
kmc.labels_
4. 참고문헌
김성수·김현중·정성석·이용구(2022), 다변량분석, 방송통신대학교출판문화원.
박서영·이기재·이긍희·장영재(2022), 통계학개론, 한국방송통신대학교출판문화원.
키워드
추천자료
 2022년 2학기 방송통신대 파이썬과R 출석수업대체과제물)R을 사용하여 다음의 자료로 3개의 ...
2022년 2학기 방송통신대 파이썬과R 출석수업대체과제물)R을 사용하여 다음의 자료로 3개의 ... 다변량분석2023년 1학기 방송통신대 다변량분석 출석수업대체과제물)R과 파이썬을 각각 이용...
다변량분석2023년 1학기 방송통신대 다변량분석 출석수업대체과제물)R과 파이썬을 각각 이용... 2023년 2학기 방송통신대 생물통계학 출석수업대체과제물)아래 첨부한 파일(생물통계학 출석...
2023년 2학기 방송통신대 생물통계학 출석수업대체과제물)아래 첨부한 파일(생물통계학 출석...- 2023년 2학기 방송통신대 파이썬과R 출석수업대체과제물)교재 연습문제 3장 (p.73) 1번, 2번,...
- 자원봉사론 2024년 1학기 중간과제물 - 자원봉사란 무엇을 의미하는지 그 개념적 요소에 대해...
- 세계의정치와경제 2024년 1학기 중간과제물 - 세계화로 인하여 국경을 넘나드는 다양한 이주 ...
- 2024년 1학기 세계의정치와경제 중간과제물) 세계화로 인하여 국경을 넘나드는 다양한 이주 ...
- 2024년 1학기 방송통신대 중간과제물 통계패키지)다음을 SAS를 이용하여 작성하시오 연습문제...
- 2024년 1학기 자원봉사론 중간과제물) 자원봉사란 무엇을 의미하는지 그 개념적 요소에 대해 ...
- 2024년 1학기 학교사회복지론 중간과제물) 학교사회복지의 개념, 필요성, 목적을 설명 자신이...
- 가격20,000원
- 페이지수17페이지
- 등록일2024.04.18
- 저작시기2024.04
- 파일형식한글(hwp)
- 자료번호#1248029

본 자료는 최근 2주간 다운받은 회원이 없습니다.



소개글