



























































-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
해당 자료는 10페이지 까지만 미리보기를 제공합니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
정 렬
1. 정렬의 정의
2. 기본적인 정렬
3. 퀵 정렬 (quick sort)
4. 힙 정렬 (heap sort)
5. 병합 정렬 (merge sort)
6. 결정 트리와 정렬 문제 복잡도의 하한선
7. 기타 정렬
1. 정렬의 정의
2. 기본적인 정렬
3. 퀵 정렬 (quick sort)
4. 힙 정렬 (heap sort)
5. 병합 정렬 (merge sort)
6. 결정 트리와 정렬 문제 복잡도의 하한선
7. 기타 정렬
본문내용
스크 : 트랙 탐색 간(seek time), 섹터 대기 시간(latency time),
자료 전송 시간(transmission time)
- 최소 밀리 초 (ms)
병합 정렬의 변형 사용
런(run) : 보조기억장치에서 일부 주기억장치로 로드하여 정렬하고
다시 보조기억장치로 저장하는 단위
병합시 런의 크기가 2배로. 런이 한 개가 되면 정렬 완료
런의 크기는 무관 (비교 중인 레코드만 주기억장치에 있으면 만족)
병합되는 런은 별도의 파일에 있어야 함
예
분석
- 최초 런의 크기가 작으면 병합 단계가 많아짐
메모리 한도 내에서 런의 크기를 최대로 하면 효율적
(예) 100만개 레코드를 크기 2 인 런에서 시작하면 20회의 패스 필요
크기 1000 인 런에서 시작하면 7회의 패스 필요
- 메모리보다 큰 런이 병합될 때는 필요 블록만 메모리에 존재
- 수행 시간에 영향을 미치는 요소
: 패스 회수, 블록 크기, 파일 입출력 시간, 파일/자료의 채널 개수
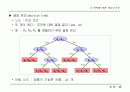
다중 병합 (multiway merging)
주기억 장치와 보조기억 장치 사이의 입출력 시간이 문제가 되는 경우
디스크와 채널의 수를 늘려 병합에 필요한 회수를 줄일 수 있음
k
개의 디스크와 채널이 있으면, 자료를
k
개의 파일로 만들어 별도의
디스크에 저장
2개의 채널을 사용하는 경우,
m
개의 런을 처리하기 위해
log sub 2 m
번 패스 필요
k
개의 채널을 사용하는 경우,
m
개의 런을 처리하기 위해
log sub k m
번 패스 필요
자료가 고루 분포되어 있으면, 패스 수를
1/log sub 2 k
만큼 줄일 수 있음
k
채널을 이용한 병합 트리
k
가 너무 클 경우
- 병합에 따른 비교 수 증가
단말노드 수가
k
힙과 같은 구조로 최소값 선택으로 해결
k
의 영향 최소화하도록
- 주기억 장치에 보관할 버퍼의 수 증가
버퍼의 크기 감소
블록의 크기 감소
디스크 입출력 회수 증가
최적의
k
는?
: 디스크 처리 속도, 버퍼용 주기억장치 크기에 의존
다상 정렬 (polyphase sorting)
k
-중 병합을 위해서는
2k
개 파일 필요
다상 정렬은
k
-중 병합을
k+1
개의 파일로 수행할 수 있도록 함
병합된 결과를 별도 파일에 저장하지 않고, 처리 마친 파일로 옮김
파일의 런 수를 조절
여러개의 파일이 비는 것 방지
파일 사용의 효율 향상
피보나치 수열 이용
피보나치 수열 :
i
번째 값 =
i-1
번째 값 +
i-2
번째 값
방법 예
- 크기 1인 34개의 런을 병합할 때
- 3개의 파일
f sub 1 ,~f sub 2 ,~ f sub 3
을 사용하여 2-중병합
-
f sub 1 ,~f sub 2
에 각각 21, 13개 런을 저장
- 13 개 런을 병합하여
f sub 3
에 저장,
f sub 1
에는 8 개 런이 남고,
f sub 1
은 비워짐
-
f sub 1 ,~f sub 3
를 병합하여
f sub 2
에 저장
- 런의 수가 1 이 될 때까지 병합 반복
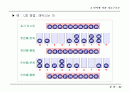
예
패스
f sub 1
f sub 2
f sub 3
초기 상태
13(1)
21(1)
-
1
-
8(1)
13(2)
2
8(3)
-
5(2)
3
3(3)
5(5)
-
4
-
2(5)
3(8)
5
2(13)
-
1(8)
6
1(13)
1(21)
-
7
-
-
1(34)
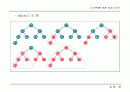
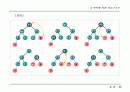
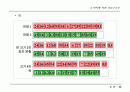
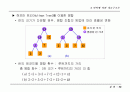
허프만 트리(Huffman Tree)를 이용한 병합
런의 크기가 다양할 경우, 병합 조합의 방법에 따라 효율성 변화
런의 레코드별 병합 횟수 : 루트까지의 거리
총 병합 회수 : (런 크기 * 루트까지의 거리) 의 합
(a)~2 times 3 + 3 times 3 + 7 times 2 + 12 times 1 = 41
(b)~2 times 2 + 3 times 2 + 7 times 2 + 12 times 2 = 48
크기가 다른
k
개의 런을
k
-중병합
차수가
k
인 병합 트리로 표시
가중치의 합이 최소가 되는 경우가 가장 효율적
허프만 트리를 이용
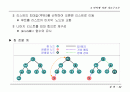
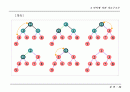
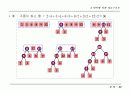
허프만 트리
- 허프만 코드를 만들기 위한 트리
허프만 코드 : 가장 빈도가 높은 문자에 대한 코드를 짧게 주는
가변형 코드 체계로서 코드의 효용성 높임
방법
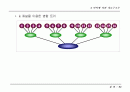
- 초기 런들을 단일 노드로 하는 포리스트 형태의 힙 구성
- 가중치가 최소인 노드를 선택하여 이진 트리 구성
- 부모 노드는 자식 노드의 합으로 생성
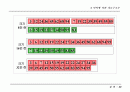
예 : 가중치 최소 합 =
2 times 4+3 times 4 + 6 times 3 + 8 times 2 + 9 times 2 + 12 times 2 = 96
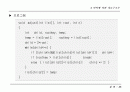
프로그램
-
n
개의 이진 트리가 heap[] 에 주어졌다고 가정
- 노드의 가중치는 weight 필드에 저장
- least() : 힙에서 최소 가중치를 선택하여 제거
- insert() : 새로운 트리를 삽입
- initialize() : 힙을 초기화
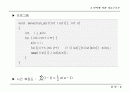
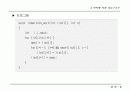
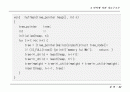
typedef struct tree_node *tree_pointer;
typedef sturct tree_node {
tree_pointer l_child;
int weight;
tree_pointer r_child;
}
tree_pointer tree;
int n;
void huffman(tree_pointer heap[], int n)
{
tree_pointer tree;
int i;
initialize(heap, n);
for (i=1;i
if (IS_FULL(tree)) {printf(\"memory full\\n\"); return; }
tree->l_child = least(heap, n-i+1);
tree->r_child = least(heap, n-i);
tree->weight = tree->l_child->weight + tree->r_child->weight;
insert(heap, n-i-1, tree);
}
}
시간 복잡도
- initialize() :
O(n)
- least(), insert() :
O(log n)
- 루프 :
n-1
번
- 전체 소요시간 :
O(n log n)
자료 전송 시간(transmission time)
- 최소 밀리 초 (ms)
병합 정렬의 변형 사용
런(run) : 보조기억장치에서 일부 주기억장치로 로드하여 정렬하고
다시 보조기억장치로 저장하는 단위
병합시 런의 크기가 2배로. 런이 한 개가 되면 정렬 완료
런의 크기는 무관 (비교 중인 레코드만 주기억장치에 있으면 만족)
병합되는 런은 별도의 파일에 있어야 함
예
분석
- 최초 런의 크기가 작으면 병합 단계가 많아짐
메모리 한도 내에서 런의 크기를 최대로 하면 효율적
(예) 100만개 레코드를 크기 2 인 런에서 시작하면 20회의 패스 필요
크기 1000 인 런에서 시작하면 7회의 패스 필요
- 메모리보다 큰 런이 병합될 때는 필요 블록만 메모리에 존재
- 수행 시간에 영향을 미치는 요소
: 패스 회수, 블록 크기, 파일 입출력 시간, 파일/자료의 채널 개수
다중 병합 (multiway merging)
주기억 장치와 보조기억 장치 사이의 입출력 시간이 문제가 되는 경우
디스크와 채널의 수를 늘려 병합에 필요한 회수를 줄일 수 있음
k
개의 디스크와 채널이 있으면, 자료를
k
개의 파일로 만들어 별도의
디스크에 저장
2개의 채널을 사용하는 경우,
m
개의 런을 처리하기 위해
log sub 2 m
번 패스 필요
k
개의 채널을 사용하는 경우,
m
개의 런을 처리하기 위해
log sub k m
번 패스 필요
자료가 고루 분포되어 있으면, 패스 수를
1/log sub 2 k
만큼 줄일 수 있음
k
채널을 이용한 병합 트리
k
가 너무 클 경우
- 병합에 따른 비교 수 증가
단말노드 수가
k
힙과 같은 구조로 최소값 선택으로 해결
k
의 영향 최소화하도록
- 주기억 장치에 보관할 버퍼의 수 증가
버퍼의 크기 감소
블록의 크기 감소
디스크 입출력 회수 증가
최적의
k
는?
: 디스크 처리 속도, 버퍼용 주기억장치 크기에 의존
다상 정렬 (polyphase sorting)
k
-중 병합을 위해서는
2k
개 파일 필요
다상 정렬은
k
-중 병합을
k+1
개의 파일로 수행할 수 있도록 함
병합된 결과를 별도 파일에 저장하지 않고, 처리 마친 파일로 옮김
파일의 런 수를 조절
여러개의 파일이 비는 것 방지
파일 사용의 효율 향상
피보나치 수열 이용
피보나치 수열 :
i
번째 값 =
i-1
번째 값 +
i-2
번째 값
방법 예
- 크기 1인 34개의 런을 병합할 때
- 3개의 파일
f sub 1 ,~f sub 2 ,~ f sub 3
을 사용하여 2-중병합
-
f sub 1 ,~f sub 2
에 각각 21, 13개 런을 저장
- 13 개 런을 병합하여
f sub 3
에 저장,
f sub 1
에는 8 개 런이 남고,
f sub 1
은 비워짐
-
f sub 1 ,~f sub 3
를 병합하여
f sub 2
에 저장
- 런의 수가 1 이 될 때까지 병합 반복
예
패스
f sub 1
f sub 2
f sub 3
초기 상태
13(1)
21(1)
-
1
-
8(1)
13(2)
2
8(3)
-
5(2)
3
3(3)
5(5)
-
4
-
2(5)
3(8)
5
2(13)
-
1(8)
6
1(13)
1(21)
-
7
-
-
1(34)
허프만 트리(Huffman Tree)를 이용한 병합
런의 크기가 다양할 경우, 병합 조합의 방법에 따라 효율성 변화
런의 레코드별 병합 횟수 : 루트까지의 거리
총 병합 회수 : (런 크기 * 루트까지의 거리) 의 합
(a)~2 times 3 + 3 times 3 + 7 times 2 + 12 times 1 = 41
(b)~2 times 2 + 3 times 2 + 7 times 2 + 12 times 2 = 48
크기가 다른
k
개의 런을
k
-중병합
차수가
k
인 병합 트리로 표시
가중치의 합이 최소가 되는 경우가 가장 효율적
허프만 트리를 이용
허프만 트리
- 허프만 코드를 만들기 위한 트리
허프만 코드 : 가장 빈도가 높은 문자에 대한 코드를 짧게 주는
가변형 코드 체계로서 코드의 효용성 높임
방법
- 초기 런들을 단일 노드로 하는 포리스트 형태의 힙 구성
- 가중치가 최소인 노드를 선택하여 이진 트리 구성
- 부모 노드는 자식 노드의 합으로 생성
예 : 가중치 최소 합 =
2 times 4+3 times 4 + 6 times 3 + 8 times 2 + 9 times 2 + 12 times 2 = 96
프로그램
-
n
개의 이진 트리가 heap[] 에 주어졌다고 가정
- 노드의 가중치는 weight 필드에 저장
- least() : 힙에서 최소 가중치를 선택하여 제거
- insert() : 새로운 트리를 삽입
- initialize() : 힙을 초기화
typedef struct tree_node *tree_pointer;
typedef sturct tree_node {
tree_pointer l_child;
int weight;
tree_pointer r_child;
}
tree_pointer tree;
int n;
void huffman(tree_pointer heap[], int n)
{
tree_pointer tree;
int i;
initialize(heap, n);
for (i=1;i
if (IS_FULL(tree)) {printf(\"memory full\\n\"); return; }
tree->l_child = least(heap, n-i+1);
tree->r_child = least(heap, n-i);
tree->weight = tree->l_child->weight + tree->r_child->weight;
insert(heap, n-i-1, tree);
}
}
시간 복잡도
- initialize() :
O(n)
- least(), insert() :
O(log n)
- 루프 :
n-1
번
- 전체 소요시간 :
O(n log n)
추천자료
- 가격3,300원
- 페이지수62페이지
- 등록일2002.12.18
- 저작시기2002.12
- 파일형식한글(hwp)
- 자료번호#215690

본 자료는 최근 2주간 다운받은 회원이 없습니다.



소개글