





























-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
해당 자료는 6페이지 까지만 미리보기를 제공합니다.
6페이지 이후부터 다운로드 후 확인할 수 있습니다.
6페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1. 자료구조의 개요
1.1 자료구조란?
1.2 알고리즘
1.3 복잡도
2. 선형 구조
2.1 배열
2.2 연결 리스트
2.3 스택
2.4 큐
3. 비 선형 구조
3.1 트리
3.2 그래프
4. 알고리즘
4.1 탐색
4.2 정렬
1.1 자료구조란?
1.2 알고리즘
1.3 복잡도
2. 선형 구조
2.1 배열
2.2 연결 리스트
2.3 스택
2.4 큐
3. 비 선형 구조
3.1 트리
3.2 그래프
4. 알고리즘
4.1 탐색
4.2 정렬
본문내용
끝 요소를 각각 상한(U)과 하한(L)의 초기 값으로 정하고 그 중간()에 위치한 레코드의 값과 찾고자 하는 키 값을 비교하여 키 값이 크면 중간 레코드 이하를, 키 값이 작으면 중간 레코드 이상을 범위에서 제외시킨다. 이와 같은 방식으로 범위를 점차 줄여 키 값을 찾을 때까지 반복한다. 만일 찾는 값이 배열 내에 없다면 범위는 0으로 줄어들게 되므로 종료한다.
(3) 피보나치 탐색
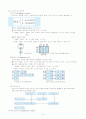
피보나치 구간이란 연속인 두 개의 피보나치 수로 이루어지는 구간을 의미한다. 피보나치 수는 식 fn=fn-1+fn-2로 구할수 있으며, 1,1,2,3,5,8,13,21...과 같이 증가한다.
26
26
31
31
32
38
38
41
43
46
50
53
58
59
79
97
↑ ↑ ↑
2 3 1
[피보나치검색]
(4) 블록 탐색
책의 목차를 보고 원하는 절을 찾아가는 방법을 적용한 것이다. 전체 배열을 몇 개의 데이터 블록으로 나누고 이 블록들에 대한 정보, 즉 색인 정보를 따로 관리한다. 우선 색인 정보를 통해 어느 블록에 있는지를 파악한 후 해당 블록 내에서 순차 탐색 등의 방법으로 최종 위치를 찾아낸다.
최대값
인덱스
31
4
41
8
53
12
97
16
[블록 색인 테이블]
(5) 해슁(hashing)
해슁은 키 값을 인자로 사용하는 해슁 함수를 이용하여 저장 주소 값을 O(1)안에 계산해내는 방법이다. 해슁 함수 h(key)는 여러 가지 방법으로 만들 수 있으며, 다음 같은 성격을 가지고 있다. h(key)는 key만의 함수이다. 그러므로 키 값 이외에 다른 값의 영향을 받지 않는다. 또한 계산 시간이 짧아야 하고 사상 시 그 분포가 고르게 나타나야 한다.
실제로 아무리 치밀한 해슁 함수를 만들어도 충돌은 발생할 수 있으며, 이때를 대비하여 해결책을 마련해야 한다. 충돌 시 해결 방법으로는 선형 방법과 비선형 방법 등이 매우 다양하게 있고, 버킷을 사용하기도 한다.
해슁 방법의 장점으로는 해슁 함수가 데이터의 양에 관계없이 일정 시간 내에 수행 가능하다는 것이다. 반면에 다른 탐색 일정한 크기의 범위를 사용해야 하므로 많은 기억 장소를 사용한다. 배정된 모든 기억 장소가 거의 다 채워진 경우 새로운 데이터가 추가되면 어떤 충돌 해결 방법을 사용하더라고 매우 잦은 충돌이 발생하게 되고 성능이 급격히 떨어질 수 있다.
4.2 정렬(sorting)
(1) 선택(selection)정렬
a[O]부터 a[n]까지의 배열 요소를 오름차순으로 정렬한다고 가정하면,
① 우선a[O]을 a[i]로 선택하고 이를 a[i+1]부터 a[n]까지 다른 모든 값과 차례로 크기를 비교하며, 선택된 자리의 값이 크면 비교 값과 바꾸고, 그렇지 않으면 비교를 계속 진행한다. 모든 비교가 마치면, 선택된 자리 a[O]에는 가장 작은 값이 저장된다.
② i를 1증가하여 다음 a[i]를 선택 한 후①의 과정을 계속 반복한다.
③ ②의 과정을 I가 n-1이 될 때까지 반복한다.
현재선택
4
2
6
3
1
5
↓ ∥ ←비교구간→ ∥
↑
최소값(선택값과 교환)
[선택정렬]
(2) 버블(bubble) 정렬
깊은 물 속으로부터 수면으로 공기 방울이 떠오르는 모습을 상상하면 이해가 쉽다.
a[O]부터 a[n]까지의 배열 요소를 오름차순으로 정렬한다고 가정하면,
① i의 초기 값을 0으로 하고 a[i+1], 즉 a[1]과 비교한다. 만일 a[i+1]이 작으면 두 값을 교환한다.
② i를 최종값 n-1까지 증가시키면서 ①을 반복한다. 이 결과 a[n]에는 가장 큰 수가 저장된다.
③ 최종 값을 1씩 감소시키며 a[1]이 최종 값이 될 때까지 ②를 반복한다.
(3) 삽입(insertion) 정렬
시험지를 학번 순으로 정렬할 때 자주 사용하는 방법이다.
a[O]부터 a[n]까지의 배열 요소를 오름차순으로 정렬한다고 가정하면,
① I를 0으로 초기화하고, a[O]부터 a[i]까지를 이미 정렬된 리스트로 가정한다.
② a[i+1]을 선택하고 이미 정렬된 리스트에서 자신의 자리를 찾아갈 동안 a[O]방향으로 버블 정렬과 같은 방식으로 하나씩 비교하며 교환해 나간다. 자신의 자리란 더 이상 자신 보다 큰수가 나타나지 않을 때까지란 의미이다.
③ I가 n보다 작을 동안 1씩 증가시키며 ②를 계속 반복한다.
(4) 퀵(quick) 정렬
a[O]부터 a[n]까지의 배열에 저장된 값을 오름차순으로 정렬한다고 가정하면, 임의의 값을 정렬될 배열의 중간 값으로 가정하고 그 보다 작은 값들은 중간 값의 왼쪽으로, 큰값들은 오른쪽으로 이동시키는 방법을 사용한다.
① 첫 번째 원소인 a[O]을 중간 값으로 가정한다. 이때 하한 i를1, 상한 j를 n으로 초기화 하고, i는 증가 시키며 중간 값 a[O]보다 큰 요소를 찾고 j는 감소시키면서 중간 값보다 작은 요소를 찾는다.
② 두 값을 교환하고 계속 새로운 값을 찾으며 반복한다.
③ i와 j의 값이 서로 교차하는 시점에서 반복을 멈추고 j가 가리키는 요소의 값과 중간 값을 교환한다.
④ 이 중간 값을 기준으로 양 쪽 구간에 대하여 ①부터 ③까지를 반복한다. 각 구간에 한 개의 요소만 남으면 종료한다.
(5) 힙(heap) 정렬
최고 힙(heap)을 구성하여 차례로 삭제하면 오름차순으로 정렬 가능하다. 이때 관건은 최소 힙을 만드는 방법이다. 최소 힙이란 임의의 노드는 자신의 모든 자식 노드보다 작거나 같은 완전 이진 트리이다.
(6) 병합(merge) 정렬
① 전체 배열을 요소의 수가 1인 부분 배열로 가정하여 두 개씩 짝을 지어 정렬한다.
② 정렬된 각각의 배열들을 다시 짝을 지어 정렬한다.
③ 최종적으로 하나의 배열로 병합될 때까지 반복한다.
(7)기수(radix)정렬
0
정렬될 데이터의 각 자릿수별로 구분하여 정렬 작업을 수행한다.
① 우선 10 자리를 현재 자릿수로 선택하고 선택된 자릿수의 값에 따라 0부터 9까지로 구분을 한다. 이때 구분된 데이터들은 각자의 큐에 위치한다.
1
2
② 각 큐의 데이터를 낮은 수, 즉 0부터 높은 수 9까지 차례로 모아 전체를 일렬로 만든다.
③ 선택된 자리를 10 (10자리), 10 (100자리)등으로 차례로 증가시키면서 가장 높은 자리까지 ①과 ②를 반복한다.
(3) 피보나치 탐색
피보나치 구간이란 연속인 두 개의 피보나치 수로 이루어지는 구간을 의미한다. 피보나치 수는 식 fn=fn-1+fn-2로 구할수 있으며, 1,1,2,3,5,8,13,21...과 같이 증가한다.
26
26
31
31
32
38
38
41
43
46
50
53
58
59
79
97
↑ ↑ ↑
2 3 1
[피보나치검색]
(4) 블록 탐색
책의 목차를 보고 원하는 절을 찾아가는 방법을 적용한 것이다. 전체 배열을 몇 개의 데이터 블록으로 나누고 이 블록들에 대한 정보, 즉 색인 정보를 따로 관리한다. 우선 색인 정보를 통해 어느 블록에 있는지를 파악한 후 해당 블록 내에서 순차 탐색 등의 방법으로 최종 위치를 찾아낸다.
최대값
인덱스
31
4
41
8
53
12
97
16
[블록 색인 테이블]
(5) 해슁(hashing)
해슁은 키 값을 인자로 사용하는 해슁 함수를 이용하여 저장 주소 값을 O(1)안에 계산해내는 방법이다. 해슁 함수 h(key)는 여러 가지 방법으로 만들 수 있으며, 다음 같은 성격을 가지고 있다. h(key)는 key만의 함수이다. 그러므로 키 값 이외에 다른 값의 영향을 받지 않는다. 또한 계산 시간이 짧아야 하고 사상 시 그 분포가 고르게 나타나야 한다.
실제로 아무리 치밀한 해슁 함수를 만들어도 충돌은 발생할 수 있으며, 이때를 대비하여 해결책을 마련해야 한다. 충돌 시 해결 방법으로는 선형 방법과 비선형 방법 등이 매우 다양하게 있고, 버킷을 사용하기도 한다.
해슁 방법의 장점으로는 해슁 함수가 데이터의 양에 관계없이 일정 시간 내에 수행 가능하다는 것이다. 반면에 다른 탐색 일정한 크기의 범위를 사용해야 하므로 많은 기억 장소를 사용한다. 배정된 모든 기억 장소가 거의 다 채워진 경우 새로운 데이터가 추가되면 어떤 충돌 해결 방법을 사용하더라고 매우 잦은 충돌이 발생하게 되고 성능이 급격히 떨어질 수 있다.
4.2 정렬(sorting)
(1) 선택(selection)정렬
a[O]부터 a[n]까지의 배열 요소를 오름차순으로 정렬한다고 가정하면,
① 우선a[O]을 a[i]로 선택하고 이를 a[i+1]부터 a[n]까지 다른 모든 값과 차례로 크기를 비교하며, 선택된 자리의 값이 크면 비교 값과 바꾸고, 그렇지 않으면 비교를 계속 진행한다. 모든 비교가 마치면, 선택된 자리 a[O]에는 가장 작은 값이 저장된다.
② i를 1증가하여 다음 a[i]를 선택 한 후①의 과정을 계속 반복한다.
③ ②의 과정을 I가 n-1이 될 때까지 반복한다.
현재선택
4
2
6
3
1
5
↓ ∥ ←비교구간→ ∥
↑
최소값(선택값과 교환)
[선택정렬]
(2) 버블(bubble) 정렬
깊은 물 속으로부터 수면으로 공기 방울이 떠오르는 모습을 상상하면 이해가 쉽다.
a[O]부터 a[n]까지의 배열 요소를 오름차순으로 정렬한다고 가정하면,
① i의 초기 값을 0으로 하고 a[i+1], 즉 a[1]과 비교한다. 만일 a[i+1]이 작으면 두 값을 교환한다.
② i를 최종값 n-1까지 증가시키면서 ①을 반복한다. 이 결과 a[n]에는 가장 큰 수가 저장된다.
③ 최종 값을 1씩 감소시키며 a[1]이 최종 값이 될 때까지 ②를 반복한다.
(3) 삽입(insertion) 정렬
시험지를 학번 순으로 정렬할 때 자주 사용하는 방법이다.
a[O]부터 a[n]까지의 배열 요소를 오름차순으로 정렬한다고 가정하면,
① I를 0으로 초기화하고, a[O]부터 a[i]까지를 이미 정렬된 리스트로 가정한다.
② a[i+1]을 선택하고 이미 정렬된 리스트에서 자신의 자리를 찾아갈 동안 a[O]방향으로 버블 정렬과 같은 방식으로 하나씩 비교하며 교환해 나간다. 자신의 자리란 더 이상 자신 보다 큰수가 나타나지 않을 때까지란 의미이다.
③ I가 n보다 작을 동안 1씩 증가시키며 ②를 계속 반복한다.
(4) 퀵(quick) 정렬
a[O]부터 a[n]까지의 배열에 저장된 값을 오름차순으로 정렬한다고 가정하면, 임의의 값을 정렬될 배열의 중간 값으로 가정하고 그 보다 작은 값들은 중간 값의 왼쪽으로, 큰값들은 오른쪽으로 이동시키는 방법을 사용한다.
① 첫 번째 원소인 a[O]을 중간 값으로 가정한다. 이때 하한 i를1, 상한 j를 n으로 초기화 하고, i는 증가 시키며 중간 값 a[O]보다 큰 요소를 찾고 j는 감소시키면서 중간 값보다 작은 요소를 찾는다.
② 두 값을 교환하고 계속 새로운 값을 찾으며 반복한다.
③ i와 j의 값이 서로 교차하는 시점에서 반복을 멈추고 j가 가리키는 요소의 값과 중간 값을 교환한다.
④ 이 중간 값을 기준으로 양 쪽 구간에 대하여 ①부터 ③까지를 반복한다. 각 구간에 한 개의 요소만 남으면 종료한다.
(5) 힙(heap) 정렬
최고 힙(heap)을 구성하여 차례로 삭제하면 오름차순으로 정렬 가능하다. 이때 관건은 최소 힙을 만드는 방법이다. 최소 힙이란 임의의 노드는 자신의 모든 자식 노드보다 작거나 같은 완전 이진 트리이다.
(6) 병합(merge) 정렬
① 전체 배열을 요소의 수가 1인 부분 배열로 가정하여 두 개씩 짝을 지어 정렬한다.
② 정렬된 각각의 배열들을 다시 짝을 지어 정렬한다.
③ 최종적으로 하나의 배열로 병합될 때까지 반복한다.
(7)기수(radix)정렬
0
정렬될 데이터의 각 자릿수별로 구분하여 정렬 작업을 수행한다.
① 우선 10 자리를 현재 자릿수로 선택하고 선택된 자릿수의 값에 따라 0부터 9까지로 구분을 한다. 이때 구분된 데이터들은 각자의 큐에 위치한다.
1
2
② 각 큐의 데이터를 낮은 수, 즉 0부터 높은 수 9까지 차례로 모아 전체를 일렬로 만든다.
③ 선택된 자리를 10 (10자리), 10 (100자리)등으로 차례로 증가시키면서 가장 높은 자리까지 ①과 ②를 반복한다.
추천자료
 [자료구조] max heap
[자료구조] max heap- [자료구조] BFS&DFS&BST
- [자료구조] post&prefix
- 자바 자료구조 족보
 (자료구조) 스택을 이용한 후위연산 소스
(자료구조) 스택을 이용한 후위연산 소스- [자료구조]Infix로 된 수식을 Prefix와 Postfix로 변환 시키는 프로그램입니다.(C언어)
 [자료구조] 배열을 이용한 다항식의 덧셈 곱셈 연산
[자료구조] 배열을 이용한 다항식의 덧셈 곱셈 연산- [자료구조] 정렬되지 않는 배열 (우선 순위 큐)
- [자료구조] 스택 함수 구현
- [자료구조] 연결 리스트를 이용한 오름차순 정리
- [자료구조] 원형 덱
 SK텔레콤 자본구조발표자료
SK텔레콤 자본구조발표자료- [자료구조] 피보나치수열 - int 데이타 사이즈를 넘어가는 결과값 계산 프로그램
- [자료구조] Linked List를 이용한 예약프로그램 - 버스예약 프로그램을 Linked_list로 구현한다
- 가격무료
- 페이지수19페이지
- 등록일2007.06.13
- 저작시기2006.10
- 파일형식한글(hwp)
- 자료번호#414698

본 자료는 최근 2주간 다운받은 회원이 없습니다.



소개글