











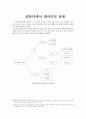













-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
해당 자료는 4페이지 까지만 미리보기를 제공합니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1. 수치 데이터의 표현
1.1 고정 소수점 표현(Fixed point)
1.2 부동 소수점 표현(Floating point)
1.3 10진 데이터
1.3.1 팩 십진수 형식
1.3.2 언팩 십진수 형식
2. 문자 데이터의 표현
2.1 이진 코드
2.1.1 BCD 코드(2진화 10진수)
2.1.2 Gray 코드
2.1.3 3-초과 코드
2.2. 알파뉴메릭 코드(alphanumeric code)
2.2.1 BCD code (2진화 10진 코드)
2.2.2 ASCII 코드
2.2.3 EBCDIC 코드
2.2.4 12비트 카드 코드
2.2.5 완성형 한글 코드
2.2.6 조합형 한글 코드
2.2.7 유니코드
3. 에러 검출 및 정정 코드
3.1 패리티 비트(parity code)
3.2 비퀴너리 코드(Biquinary code)
3.3 해밍 코드(Hamming code)
3.4 2 Out Of 5 코드
3.5 2 Ring-counter Code
1.1 고정 소수점 표현(Fixed point)
1.2 부동 소수점 표현(Floating point)
1.3 10진 데이터
1.3.1 팩 십진수 형식
1.3.2 언팩 십진수 형식
2. 문자 데이터의 표현
2.1 이진 코드
2.1.1 BCD 코드(2진화 10진수)
2.1.2 Gray 코드
2.1.3 3-초과 코드
2.2. 알파뉴메릭 코드(alphanumeric code)
2.2.1 BCD code (2진화 10진 코드)
2.2.2 ASCII 코드
2.2.3 EBCDIC 코드
2.2.4 12비트 카드 코드
2.2.5 완성형 한글 코드
2.2.6 조합형 한글 코드
2.2.7 유니코드
3. 에러 검출 및 정정 코드
3.1 패리티 비트(parity code)
3.2 비퀴너리 코드(Biquinary code)
3.3 해밍 코드(Hamming code)
3.4 2 Out Of 5 코드
3.5 2 Ring-counter Code
본문내용
된 코드체계)이 업계표준으로 규정한 만국공통 문자코드이다
미국에서 개발되어진 컴퓨터는 그 구조가 영어를 바탕으로 정의되어 있기에 8비트로 표현할 수 있는 256자는 영어나 라틴권 등에서는 문제가 없으나, 한국, 일본, 중국, 아랍 등의 다양한 문자들을 표현하는 데는 한계가 있다. 또한 각 나라마다 같은 코드 값에 다른 글자를 쓰는 방식으로는 국제간의 원활한 자료 교환이 불가능하기 때문에 코드를 16비트 체제로 확장해서 65,536자의 영역 안에 전 세계의 모든 글자를 표시하는 표준안인 것이다.
영어를 사용하는 국가에서는 아스키 코드보다 두 배의 공간이 필요하기 때문에 일반적인 통신 등에서는 그만큼의 낭비가 되지만 유니코드를 이용하면 프로그램을 하나만 만들면 모든 나라들의 글자를 처리할 수 있기 때문에 그만큼 큰 이점도 되는 것이다.
기본적으로 유니코드에서는 16비트를 사용하여 하나의 문자를 표현하고 있다. 유니코드 컨소시엄은 91년 만국공통의 문자코드를 제정, 보급하기 위해 창설됐으며 현재 북미.유럽.아시아 등에서 45개 주요기업이 참여하고 있다. 최근 "유니코드3.0"을 출시 했으며 국가 단위의 국제기구인 ISO와 공동표준규격 마련 및 개발자 기술지원서비스를 병행하고 있다.
"유니코드2.0"에는 모두 6만5천5백36자(OXOOOO~OXFFFF)의 코드영역이 있는데 이 가운데 3만8천8백85자는 주요 국가언어 구현용으로 이미 할당되어 있고 6천4백자는 사용자 정의 영역(Private Use Area)으로, 2만2백49자는 향후 새로 추가될 언어영역(Future Use Area)으로 각각 비워두고 있다. 현재할당된 주요 언어는 아스키(미국표준정보교환코드),그리스어,라틴어,시릴문자,히브리어,타이어,기호문자(Symbols),함수문자(Punctuation),아랍어,가나,모(Hangul Jamo),CJK(중.일.한 공통한자)영역, 표의문자(한자), 한글(HangulSyllables), 대용문자(Surrogates) 등이다.
코드할당비율을 보면 한자가 39.89%(2만9백2자)로 가장 많고 그 다음이 한글 17.04%(1만1천1백72자), 아스키 및 기호문자 10.39%(6천8백11자) 등의 순이다.
우리나라에서도 지난 96년 2월16일 서울 롯데호텔에서 설명회를 열었고 우리나라에서도 다양한 서체가 개발되고 있다.
11,172자의 한글을 연속된 공간에 가나다라 순서로 '가'에서 'ㅎ'까지를 코드화하는 방식이 유니코드 기술 위원회(UTC)에서 채택한 유니코드 2.0 규격이다.
3. 에러 검출 및 정정 코드
3.1 패리티 비트(parity code)
정보 비트에 1비트 여유 비트를 부가하여 전체 비트 중에서 1 또는 0의 개수를 홀수나 짝수로 하여 오류 검출을 할 수 있도록 만든 코드이나 전송 중에 두 비트가 동시에 변한다면 에러 검출이 불가능하다.
3.2 비퀴너리 코드(Biquinary code)
혼합 기수 표기법의 하나로, 10진수를 표현하는 데 각각 1자리를 2개의 숫자의 합으로 나타내는 것, 그 최초의 숫자는 0이나 1이며, 그 값은 그 숫자에 5를 곱한 것과 같고 두 번째의 숫자는 0,1,2,3,4, 중의 하나로서, 그 값은 그 숫자에 1을 곱한 것(숫자 자체의 값)과 같다. 결국 이 코드는 오류 검출을 위한 코드의 한 방법으로서 다음과 같이 구성되어 있다.
10진수
5 0 4 3 2 1 0
0
0 1 0 0 0 0 1
1
0 1 0 0 0 1 0
2
0 1 0 0 1 0 0
3
0 1 0 1 0 0 0
4
0 1 1 0 0 0 0
5
1 0 0 0 0 0 1
6
1 0 0 0 0 1 0
7
1 0 0 0 1 0 0
8
1 0 0 1 0 0 0
9
1 0 1 0 0 0 0
이 코드는 각 그룹에 1이 반드시 2개 포함되어 있으므로 어느 한 비트에 오류가 발생하면 1의 개수가 달라져 오류를 검출할 수 있다. 그러나 1이 0으로, 0이 1로 바뀌면 1의 합계수 2개에는 변함이 없어 오류를 검출할 수 없다.
3.3 해밍 코드(Hamming code)
미국 Bell 연구소
Bell laboratory [벨 연구소] : 미국 뉴저지 주에 있는 컴퓨터 및 전자 공학 부분에서 많은 업적을 낸 연구소
의 해밍(Hamming)
수학자 리처드 웨슬리 해밍(Richard Wesley Hamming, 1916 1988)
에 의하여 고안된 코드 체계로서 한 비트의 오류를 자동적으로 정정해 주는 코드이다. 이 코드는 3개의 여분 비트(영숫자일 경우에는 4개의 여분 비트)를 추가하여 단일 오류를 정정할 수 있으며, 2개 이상의 종복된 오류를 정정하려면 이보다 더 많은 여분의 비트가 필요하다.
오늘날에는 휴대전화나 콤팩트디스크 등에서 신호의 오류를 수정하거나, 자료를 압축해 인터넷 속도를 향상시킬 때 유용하게 쓰인다.
예) 원래의 코드가 0011001이고, 짝수 패리티를 수행한다고 했을 때, 전송 후 에러가 발생하여 0010001이 수신 되었다고 가정하자.
비트 표시
P1
P2
M1
P3
M2
M3
M4
비트 자리
1
2
3
4
5
6
7
수신 비트
0
0
1
0
0
0
1
P1은 비트 자리 1, 3, 5, 7을 점검하여 두 개의 1이 있으므로 오류가 없고, 따라서 0이 된다. P2는 비트 자리 2, 3, 6, 7을 점검하여 두 개의 1이 있으므로 오류가 없고, 따라서 0이 된다. P3는 비트 자리 4, 5, 6, 7을 점검하여 한 개의 1이 있으므로 오류가 발생하였고, 따라서 1이 된다. 결과적으로 만들어 진 2 진 숫자는 P3P2P1 자리 순으로 하면 100이 되고, 이 값에 따라 네 번째 자리에 오류가 발생 하였음을 알 수 있다.
3.4 2 Out Of 5 코드
자리 결정 기수법의 하나로서 10진 숫자를 5개의 2진 숫자에 의해서 나타내는 것, 즉, 5개 중 2개가 1을 나타내고 3개는 0을 나타내거나 또는 이와 반대의 방법으로 표현한다.
3.5 2 Ring-Counter Code(링 카운터 코드)
링 카운터 코드는 10개의 비트로 구성되어 있으며, 모든 코드가 하나의 비트에 반드시 1을 가진다. 이것은 에러 검출과 코드를 만들기 위한 디지털 회로를 작동시키는데 용이하게 사용된다.
미국에서 개발되어진 컴퓨터는 그 구조가 영어를 바탕으로 정의되어 있기에 8비트로 표현할 수 있는 256자는 영어나 라틴권 등에서는 문제가 없으나, 한국, 일본, 중국, 아랍 등의 다양한 문자들을 표현하는 데는 한계가 있다. 또한 각 나라마다 같은 코드 값에 다른 글자를 쓰는 방식으로는 국제간의 원활한 자료 교환이 불가능하기 때문에 코드를 16비트 체제로 확장해서 65,536자의 영역 안에 전 세계의 모든 글자를 표시하는 표준안인 것이다.
영어를 사용하는 국가에서는 아스키 코드보다 두 배의 공간이 필요하기 때문에 일반적인 통신 등에서는 그만큼의 낭비가 되지만 유니코드를 이용하면 프로그램을 하나만 만들면 모든 나라들의 글자를 처리할 수 있기 때문에 그만큼 큰 이점도 되는 것이다.
기본적으로 유니코드에서는 16비트를 사용하여 하나의 문자를 표현하고 있다. 유니코드 컨소시엄은 91년 만국공통의 문자코드를 제정, 보급하기 위해 창설됐으며 현재 북미.유럽.아시아 등에서 45개 주요기업이 참여하고 있다. 최근 "유니코드3.0"을 출시 했으며 국가 단위의 국제기구인 ISO와 공동표준규격 마련 및 개발자 기술지원서비스를 병행하고 있다.
"유니코드2.0"에는 모두 6만5천5백36자(OXOOOO~OXFFFF)의 코드영역이 있는데 이 가운데 3만8천8백85자는 주요 국가언어 구현용으로 이미 할당되어 있고 6천4백자는 사용자 정의 영역(Private Use Area)으로, 2만2백49자는 향후 새로 추가될 언어영역(Future Use Area)으로 각각 비워두고 있다. 현재할당된 주요 언어는 아스키(미국표준정보교환코드),그리스어,라틴어,시릴문자,히브리어,타이어,기호문자(Symbols),함수문자(Punctuation),아랍어,가나,모(Hangul Jamo),CJK(중.일.한 공통한자)영역, 표의문자(한자), 한글(HangulSyllables), 대용문자(Surrogates) 등이다.
코드할당비율을 보면 한자가 39.89%(2만9백2자)로 가장 많고 그 다음이 한글 17.04%(1만1천1백72자), 아스키 및 기호문자 10.39%(6천8백11자) 등의 순이다.
우리나라에서도 지난 96년 2월16일 서울 롯데호텔에서 설명회를 열었고 우리나라에서도 다양한 서체가 개발되고 있다.
11,172자의 한글을 연속된 공간에 가나다라 순서로 '가'에서 'ㅎ'까지를 코드화하는 방식이 유니코드 기술 위원회(UTC)에서 채택한 유니코드 2.0 규격이다.
3. 에러 검출 및 정정 코드
3.1 패리티 비트(parity code)
정보 비트에 1비트 여유 비트를 부가하여 전체 비트 중에서 1 또는 0의 개수를 홀수나 짝수로 하여 오류 검출을 할 수 있도록 만든 코드이나 전송 중에 두 비트가 동시에 변한다면 에러 검출이 불가능하다.
3.2 비퀴너리 코드(Biquinary code)
혼합 기수 표기법의 하나로, 10진수를 표현하는 데 각각 1자리를 2개의 숫자의 합으로 나타내는 것, 그 최초의 숫자는 0이나 1이며, 그 값은 그 숫자에 5를 곱한 것과 같고 두 번째의 숫자는 0,1,2,3,4, 중의 하나로서, 그 값은 그 숫자에 1을 곱한 것(숫자 자체의 값)과 같다. 결국 이 코드는 오류 검출을 위한 코드의 한 방법으로서 다음과 같이 구성되어 있다.
10진수
5 0 4 3 2 1 0
0
0 1 0 0 0 0 1
1
0 1 0 0 0 1 0
2
0 1 0 0 1 0 0
3
0 1 0 1 0 0 0
4
0 1 1 0 0 0 0
5
1 0 0 0 0 0 1
6
1 0 0 0 0 1 0
7
1 0 0 0 1 0 0
8
1 0 0 1 0 0 0
9
1 0 1 0 0 0 0
이 코드는 각 그룹에 1이 반드시 2개 포함되어 있으므로 어느 한 비트에 오류가 발생하면 1의 개수가 달라져 오류를 검출할 수 있다. 그러나 1이 0으로, 0이 1로 바뀌면 1의 합계수 2개에는 변함이 없어 오류를 검출할 수 없다.
3.3 해밍 코드(Hamming code)
미국 Bell 연구소
Bell laboratory [벨 연구소] : 미국 뉴저지 주에 있는 컴퓨터 및 전자 공학 부분에서 많은 업적을 낸 연구소
의 해밍(Hamming)
수학자 리처드 웨슬리 해밍(Richard Wesley Hamming, 1916 1988)
에 의하여 고안된 코드 체계로서 한 비트의 오류를 자동적으로 정정해 주는 코드이다. 이 코드는 3개의 여분 비트(영숫자일 경우에는 4개의 여분 비트)를 추가하여 단일 오류를 정정할 수 있으며, 2개 이상의 종복된 오류를 정정하려면 이보다 더 많은 여분의 비트가 필요하다.
오늘날에는 휴대전화나 콤팩트디스크 등에서 신호의 오류를 수정하거나, 자료를 압축해 인터넷 속도를 향상시킬 때 유용하게 쓰인다.
예) 원래의 코드가 0011001이고, 짝수 패리티를 수행한다고 했을 때, 전송 후 에러가 발생하여 0010001이 수신 되었다고 가정하자.
비트 표시
P1
P2
M1
P3
M2
M3
M4
비트 자리
1
2
3
4
5
6
7
수신 비트
0
0
1
0
0
0
1
P1은 비트 자리 1, 3, 5, 7을 점검하여 두 개의 1이 있으므로 오류가 없고, 따라서 0이 된다. P2는 비트 자리 2, 3, 6, 7을 점검하여 두 개의 1이 있으므로 오류가 없고, 따라서 0이 된다. P3는 비트 자리 4, 5, 6, 7을 점검하여 한 개의 1이 있으므로 오류가 발생하였고, 따라서 1이 된다. 결과적으로 만들어 진 2 진 숫자는 P3P2P1 자리 순으로 하면 100이 되고, 이 값에 따라 네 번째 자리에 오류가 발생 하였음을 알 수 있다.
3.4 2 Out Of 5 코드
자리 결정 기수법의 하나로서 10진 숫자를 5개의 2진 숫자에 의해서 나타내는 것, 즉, 5개 중 2개가 1을 나타내고 3개는 0을 나타내거나 또는 이와 반대의 방법으로 표현한다.
3.5 2 Ring-Counter Code(링 카운터 코드)
링 카운터 코드는 10개의 비트로 구성되어 있으며, 모든 코드가 하나의 비트에 반드시 1을 가진다. 이것은 에러 검출과 코드를 만들기 위한 디지털 회로를 작동시키는데 용이하게 사용된다.
추천자료
- 가격1,000원
- 페이지수13페이지
- 등록일2003.11.25
- 저작시기2003.11
- 파일형식한글(hwp)
- 자료번호#234488

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글