























-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
해당 자료는 4페이지 까지만 미리보기를 제공합니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
제1장. 통계학의 이해 1
1. 통계학의 어원 1
2. 통계학의 정의 1
3. 통계학의 종류 1
제2장. 모집관과 표본 2
1. 모집단과 표본 3
2. 전수조사에 비해 표본조사를 하는 이유 및 장점 3
3. 비확률추출법과 확률추출법 4
4. 확률추출법 4
5. 확률추출법에 의한 표본 추출방법 4
제3장. 자료의 수집과 정리 5
1. 자료의 종류 5
2. 질적 자료의 정리 5
3. 양적 자료의 정리 6
제4장. 자료의 통계적 측정(기술통계 분석) 6
1. 중심위치의 측도 6
2. 산포도 7
제5장. 확률분포와 정규분포 8
1. 분포 8
2. 확률분포 9
3. 정규분포 10
4. 중심극한 정리 11
제6장. 추정과 가설검정(T-test) 11
1. 가설검정의 절차 11
1. 통계학의 어원 1
2. 통계학의 정의 1
3. 통계학의 종류 1
제2장. 모집관과 표본 2
1. 모집단과 표본 3
2. 전수조사에 비해 표본조사를 하는 이유 및 장점 3
3. 비확률추출법과 확률추출법 4
4. 확률추출법 4
5. 확률추출법에 의한 표본 추출방법 4
제3장. 자료의 수집과 정리 5
1. 자료의 종류 5
2. 질적 자료의 정리 5
3. 양적 자료의 정리 6
제4장. 자료의 통계적 측정(기술통계 분석) 6
1. 중심위치의 측도 6
2. 산포도 7
제5장. 확률분포와 정규분포 8
1. 분포 8
2. 확률분포 9
3. 정규분포 10
4. 중심극한 정리 11
제6장. 추정과 가설검정(T-test) 11
1. 가설검정의 절차 11
본문내용
an)
: 평균은 중심위치의 측도로서 가장 많이 사용되고 있으며, 양적자료에만 사용된다.
평균 =
(2) 중앙값(Median)
중앙값은 자료를 크기 순으로 나열할 때 가운데에 위치한 값이다.
모평균과 표본평균의 정의
모집단의 자료수 : N, 표본의 자료수 : n
모평균 μ = ( + + … + ) =
표본평균 = ( + + … + ) =
(3) 최빈값(Mode)
2. 산포도(Measure of dispersion)
자료가 평균과 같은 중심위치에서 얼마만큼 떨어져 있는가를 측정하는 측도가 필요하며 이 측도를 산포도라고 한다.
(1) 분산과 표준편차
산포도로서 가장 많이 쓰이는 것이 분산과 표준편차이다.
5 9 8 6 3 7 4
이 자료의 평균은 6이며, 각 자료 값과 평균과의 차이인 편차는
-1 3 2 0 -3 1 -2
와 같다. 이러한 편차의 제곱의 합을 사용하는 것이 분산과 표준편차이다.
표본일 경우 분모가 n대신에 n-1을 사용한다.
(2) 변이계수(coefficient of variation)
두 집간의 산포를 비교할 때 두 종류의 자료 값의 차이가 크거나, 측정단위가 다른 두 그룹의 산포를 비교하고자 할 때 유용하게 쓰인다.
변동계수 : CV = x 100
(3) 범위
범위(Range) = 최대값(max) - 최소값(min) 으로 결정되며, 가장 간단한 산포도이나 결점은 두 극단의 값에 의해 정해지므로, 그 하나가 예외적인 것이라면 곧 그 값이 반영된다.
(4) 백분위수
(5) 사분위수
사분위수는 데이터를 4등분하는 기준점이라고 할 수 있다. 크기순으로 데이터를 나열하여 하위 25% 50% 75%에 해당되는 기준점을 각각 제1사분위수, 제2사분위수, 제3사분위수라고 한다. 그러므로 제2사분위수는 중앙값이 된다.
25%
25%
25%
25%
최소값 Q1 중앙값(Q2) Q3 최대값
또한 분포의 형태를 나타내는 척도로서 왜도와 첨도가 있다.
(1) 왜도(skewness) - 자료가 얼마나 치우쳐있나 (S)
왜도 > 0 - 오른쪽으로 기울어짐
왜도 = 0 - 분포가 대칭
왜도 < 0 - 왼쪽으로 기울어짐
(2) 첨도(kurtosis) : (K)
첨도는 분포의 모양이 얼마나 뾰족한가를 측정하는 통계치이다. 정규분포의 첨도는 0이며, 정규분포에 비해 봉우리가 더 뾰족하면 첨도는 0보다 크다.
제 5 장. 확률분포와 정규분포
1. 분포(Distribution)
분포(Distribution)란 자료가 흩어져 있는 형태를 말하는 것으로, 다양한 형태의 그래프를 통해서 그 형태를 나타낼 수가 있다. 이러한 분포는 자료의 특성을 파악하는데 있어서 중심위치나 산포도와 더불어 매우 중요한 요인이 된다.
자료A (9,9,9,10,11,11,11) 자료B(8,10,10,10,10,11,11)
자료 A, 자료 B - 평균(10), 표준편차(1) 동일함. 두 그룹이 성질이 같다??
※ 자료들의 특성을 파악하기 위해서는 그 자료들의 중심위치, 산포도뿐만 아니라 분포의 형태도 파악해야 한다.
2. 확률분포
(1) 확률변수
확률변수(random variable)란 통계적인 실험의 결과들에 어떤 수치적인 특성을 대응시키는 함수를 말한다.
예를 들어, 동전을 두 번 던지는 실험에서 앞면이 나오는 횟수를 X라고 할 때, X가 가질 수 있는 값들은 아래와 같이 0, 1, 2가 될 것이고, 실험을 하기 전에는 X가 어떤 값을 갖는지 예측학가 불가능하므로, 결국 X는 확률변수가 된다. 따라서 X가 1이라고 한다면, 이는 동전을 두 번 던져서 앞면이 한번 나오는 경우를 뜻하는 것이 된다.
실험의 결과
(첫번째, 두 번째)
(앞면, 뒷면)
(앞면, 뒷면)
(뒷면, 앞면)
(뒷면, 뒷면)
대응되는 X값
2
1
0
(2) 확률분포
확률분포(probability distribution)는 확률변수들이 갖는 값에 따라 만들어지는 사상들과 그 확률을 대응시켜주는 관계를 말한다. 따라서 확률변수 X의 확률분포는 X가 갖는 값들과 이에 대응되는 확률들로 나타난다.
X의 값 :
2
1
0
합계
확률 : P(X=
1/4
2/4
1/4
1
3. 정규분포
1) 정규분포(normal distribution)는 통계이론에서 가장 중요한 확률분포이다.
2) 정규분포의 특징
① 평균을 중심으로 좌우대칭이며 종모양
② 정규곡선은 x축에 무한대로 수렴
③ 평균과 분산(또는 표준편차)에 의해 분포의 모양이 결정됨
④ 곡선 아래 면접의 합 = 1
⑤ ± 1 (S D) ; 68 %
± 2 (S D) ; 95 %
± 3 (S D) ; 99 %
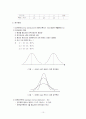
<그림 - > 분산이 같고 평균이 다른 정규분포
<그림 - > 평균이 같고 분산이 다른 정규분포
3) 표준정규분포 (standard normal distribution ; SD)
- 정규분포 중에서 평균이 0 이고, 분산이 1 인 경우
- 표준정규분포는 0을 중심으로 좌우대칭이 된다.
- 정규분포의 표준화
Z = ~ N(0, 1)
4. 중심극한정리
: 표본의 크기가 일정규모 이상이 되면 표본평균의 분포는 모집단의 분포가 어떤 형태이든 관계없이 평균과 분산이 존재하면 근사적으로 항상 정규분포를 따르게 된다고 알려져 있다. 표본평균의 분포에 대한 이러한 특성을 중심극한정리(central limit theorem)라고 하는데, 이 정리는 표본의 크기는 대략 30 이상이면 비교적 만족되어 진다고 한다.
.
제 6 장. 추정과 가설검정(T-test)
1. 가설검정의 절차
1) 가설의 설정
: 가설검정에서 설정해야할 가설은 두 가지로 구분된다.
첫째, 귀무가설(null hypothesis : H )
[ = ]
둘째, 대립가설(alternative hypothesis : H)
[ , < , > ; 양측검증, 단측검증 ]
[ ; 단측검증 ]
2) 유의수준 결정
① = 0.01 ( 1% 유의수준)
② = 0.05 ( 5% 유의수준) … 보통 많이 쓴다.
③ = 0.1 ( 10% 유의수준)
3) H의 가설의 기각 여부 결정
P 값 < 0.05 → H 가설 기각 (reject)
H 가설 채택 (accept)
4) 결과 해석
H 기각
H 채택 → 두 집단 간에는 통계적으로 유의한 차이가 있다.
: 평균은 중심위치의 측도로서 가장 많이 사용되고 있으며, 양적자료에만 사용된다.
평균 =
(2) 중앙값(Median)
중앙값은 자료를 크기 순으로 나열할 때 가운데에 위치한 값이다.
모평균과 표본평균의 정의
모집단의 자료수 : N, 표본의 자료수 : n
모평균 μ = ( + + … + ) =
표본평균 = ( + + … + ) =
(3) 최빈값(Mode)
2. 산포도(Measure of dispersion)
자료가 평균과 같은 중심위치에서 얼마만큼 떨어져 있는가를 측정하는 측도가 필요하며 이 측도를 산포도라고 한다.
(1) 분산과 표준편차
산포도로서 가장 많이 쓰이는 것이 분산과 표준편차이다.
5 9 8 6 3 7 4
이 자료의 평균은 6이며, 각 자료 값과 평균과의 차이인 편차는
-1 3 2 0 -3 1 -2
와 같다. 이러한 편차의 제곱의 합을 사용하는 것이 분산과 표준편차이다.
표본일 경우 분모가 n대신에 n-1을 사용한다.
(2) 변이계수(coefficient of variation)
두 집간의 산포를 비교할 때 두 종류의 자료 값의 차이가 크거나, 측정단위가 다른 두 그룹의 산포를 비교하고자 할 때 유용하게 쓰인다.
변동계수 : CV = x 100
(3) 범위
범위(Range) = 최대값(max) - 최소값(min) 으로 결정되며, 가장 간단한 산포도이나 결점은 두 극단의 값에 의해 정해지므로, 그 하나가 예외적인 것이라면 곧 그 값이 반영된다.
(4) 백분위수
(5) 사분위수
사분위수는 데이터를 4등분하는 기준점이라고 할 수 있다. 크기순으로 데이터를 나열하여 하위 25% 50% 75%에 해당되는 기준점을 각각 제1사분위수, 제2사분위수, 제3사분위수라고 한다. 그러므로 제2사분위수는 중앙값이 된다.
25%
25%
25%
25%
최소값 Q1 중앙값(Q2) Q3 최대값
또한 분포의 형태를 나타내는 척도로서 왜도와 첨도가 있다.
(1) 왜도(skewness) - 자료가 얼마나 치우쳐있나 (S)
왜도 > 0 - 오른쪽으로 기울어짐
왜도 = 0 - 분포가 대칭
왜도 < 0 - 왼쪽으로 기울어짐
(2) 첨도(kurtosis) : (K)
첨도는 분포의 모양이 얼마나 뾰족한가를 측정하는 통계치이다. 정규분포의 첨도는 0이며, 정규분포에 비해 봉우리가 더 뾰족하면 첨도는 0보다 크다.
제 5 장. 확률분포와 정규분포
1. 분포(Distribution)
분포(Distribution)란 자료가 흩어져 있는 형태를 말하는 것으로, 다양한 형태의 그래프를 통해서 그 형태를 나타낼 수가 있다. 이러한 분포는 자료의 특성을 파악하는데 있어서 중심위치나 산포도와 더불어 매우 중요한 요인이 된다.
자료A (9,9,9,10,11,11,11) 자료B(8,10,10,10,10,11,11)
자료 A, 자료 B - 평균(10), 표준편차(1) 동일함. 두 그룹이 성질이 같다??
※ 자료들의 특성을 파악하기 위해서는 그 자료들의 중심위치, 산포도뿐만 아니라 분포의 형태도 파악해야 한다.
2. 확률분포
(1) 확률변수
확률변수(random variable)란 통계적인 실험의 결과들에 어떤 수치적인 특성을 대응시키는 함수를 말한다.
예를 들어, 동전을 두 번 던지는 실험에서 앞면이 나오는 횟수를 X라고 할 때, X가 가질 수 있는 값들은 아래와 같이 0, 1, 2가 될 것이고, 실험을 하기 전에는 X가 어떤 값을 갖는지 예측학가 불가능하므로, 결국 X는 확률변수가 된다. 따라서 X가 1이라고 한다면, 이는 동전을 두 번 던져서 앞면이 한번 나오는 경우를 뜻하는 것이 된다.
실험의 결과
(첫번째, 두 번째)
(앞면, 뒷면)
(앞면, 뒷면)
(뒷면, 앞면)
(뒷면, 뒷면)
대응되는 X값
2
1
0
(2) 확률분포
확률분포(probability distribution)는 확률변수들이 갖는 값에 따라 만들어지는 사상들과 그 확률을 대응시켜주는 관계를 말한다. 따라서 확률변수 X의 확률분포는 X가 갖는 값들과 이에 대응되는 확률들로 나타난다.
X의 값 :
2
1
0
합계
확률 : P(X=
1/4
2/4
1/4
1
3. 정규분포
1) 정규분포(normal distribution)는 통계이론에서 가장 중요한 확률분포이다.
2) 정규분포의 특징
① 평균을 중심으로 좌우대칭이며 종모양
② 정규곡선은 x축에 무한대로 수렴
③ 평균과 분산(또는 표준편차)에 의해 분포의 모양이 결정됨
④ 곡선 아래 면접의 합 = 1
⑤ ± 1 (S D) ; 68 %
± 2 (S D) ; 95 %
± 3 (S D) ; 99 %
<그림 - > 분산이 같고 평균이 다른 정규분포
<그림 - > 평균이 같고 분산이 다른 정규분포
3) 표준정규분포 (standard normal distribution ; SD)
- 정규분포 중에서 평균이 0 이고, 분산이 1 인 경우
- 표준정규분포는 0을 중심으로 좌우대칭이 된다.
- 정규분포의 표준화
Z = ~ N(0, 1)
4. 중심극한정리
: 표본의 크기가 일정규모 이상이 되면 표본평균의 분포는 모집단의 분포가 어떤 형태이든 관계없이 평균과 분산이 존재하면 근사적으로 항상 정규분포를 따르게 된다고 알려져 있다. 표본평균의 분포에 대한 이러한 특성을 중심극한정리(central limit theorem)라고 하는데, 이 정리는 표본의 크기는 대략 30 이상이면 비교적 만족되어 진다고 한다.
.
제 6 장. 추정과 가설검정(T-test)
1. 가설검정의 절차
1) 가설의 설정
: 가설검정에서 설정해야할 가설은 두 가지로 구분된다.
첫째, 귀무가설(null hypothesis : H )
[ = ]
둘째, 대립가설(alternative hypothesis : H)
[ , < , > ; 양측검증, 단측검증 ]
[ ; 단측검증 ]
2) 유의수준 결정
① = 0.01 ( 1% 유의수준)
② = 0.05 ( 5% 유의수준) … 보통 많이 쓴다.
③ = 0.1 ( 10% 유의수준)
3) H의 가설의 기각 여부 결정
P 값 < 0.05 → H 가설 기각 (reject)
H 가설 채택 (accept)
4) 결과 해석
H 기각
H 채택 → 두 집단 간에는 통계적으로 유의한 차이가 있다.
추천자료
- 가격2,000원
- 페이지수12페이지
- 등록일2005.10.19
- 저작시기2005.10
- 파일형식한글(hwp)
- 자료번호#316329

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글