













-
1
-
2
-
3
-
4
-
5
-
6
해당 자료는 2페이지 까지만 미리보기를 제공합니다.
2페이지 이후부터 다운로드 후 확인할 수 있습니다.
2페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1. Uniform
(1) pdf/cdf
(2) pdf/cdf 랜덤 샘플 20000개
(3) 분석
2. exponential
(1) pdf/cdf
(2) pdf/cdf 랜덤 샘플 20000개
(3) 분석
3. gaussian
(1) pdf/cdf
(2) pdf/cdf 랜덤 샘플 20000개
(3) 분석
(1) pdf/cdf
(2) pdf/cdf 랜덤 샘플 20000개
(3) 분석
2. exponential
(1) pdf/cdf
(2) pdf/cdf 랜덤 샘플 20000개
(3) 분석
3. gaussian
(1) pdf/cdf
(2) pdf/cdf 랜덤 샘플 20000개
(3) 분석
본문내용
더 작게 둘수록 매끄러운 그래프가 나오지만 샘플을 생성할 때는 흐트러지는 것을 볼 수 있었다. 샘플한 것을 살펴보면 pdf에 비해 CDF는 거의 흡사하다는 것을 볼 수 있다. 그 이유는 pdf에서는 x값 하나에 값이 들어가는 반면 CDF에서는 이것을 적분한 형태이기 때문이라고 생각이 든다.
샘플을 적게 생성할수록 pdf에서 양쪽 끝이 많이 변하는 모습을 살펴볼 수 있으며 샘플을 많이 생성하게 되면 원래의 그래프와 더 흡사한 형태가 나온다는 것을 확인할 수 있다.
3. gaussian
(1) pdf/cdf
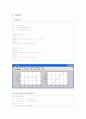
x = -4:0.05:8
y = gausspdf(2,1.5,x)
z = gausscdf(2,1.5,x)
subplot(1,2,1)
plot (x, y)
subplot(1,2,1), axis([-4 8 0 0.4])
grid on
xlabel('x'); ylabel('pdf');
subplot(1,2,2)
plot(x, z)
subplot(1,2,2), axis([-4 8 0 1])
grid on
xlabel('x'); ylabel('cdf');
(2) pdf/cdf 랜덤 샘플 20000개
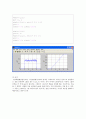
x = -4:0.05:8
y = gaussrv (2,1.5,20000)
z = (hist(y,x) / (20000*0.05))
count (y, 2)
w = count (y, x)/20000
subplot(1,2,1)
plot (x, z)
subplot(1,2,1), axis([-4 8 0 0.4])
grid on
xlabel('x'); ylabel('pdf');
subplot(1,2,2)
plot(x, w)
subplot(1,2,2), axis([-4 8 0 1])
grid on
xlabel('x'); ylabel('cdf');
(3) 분석
연속함수이지만 x값을 이산형태로 줄 수밖에 없기 때문에 x값의 간격 매우 작게 두었다. x값을 더 작게 둘수록 매끄러운 그래프가 나오지만 샘플을 생성할 때는 흐트러지는 것을 볼 수 있었다. 샘플한 것을 살펴보면 pdf에 비해 CDF는 거의 흡사하다는 것을 볼 수 있다. 그 이유는 pdf에서는 x값 하나에 값이 들어가는 반면 CDF에서는 이것을 적분한 형태이기 때문이라고 생각이 든다.
샘플을 적게 생성할수록 pdf에서 양쪽 끝이 많이 변하는 모습을 살펴볼 수 있으며 샘플을 많이 생성하게 되면 원래의 그래프와 더 흡사한 형태가 나온다는 것을 확인할 수 있다.
샘플을 적게 생성할수록 pdf에서 양쪽 끝이 많이 변하는 모습을 살펴볼 수 있으며 샘플을 많이 생성하게 되면 원래의 그래프와 더 흡사한 형태가 나온다는 것을 확인할 수 있다.
3. gaussian
(1) pdf/cdf
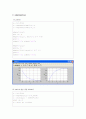
x = -4:0.05:8
y = gausspdf(2,1.5,x)
z = gausscdf(2,1.5,x)
subplot(1,2,1)
plot (x, y)
subplot(1,2,1), axis([-4 8 0 0.4])
grid on
xlabel('x'); ylabel('pdf');
subplot(1,2,2)
plot(x, z)
subplot(1,2,2), axis([-4 8 0 1])
grid on
xlabel('x'); ylabel('cdf');
(2) pdf/cdf 랜덤 샘플 20000개
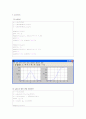
x = -4:0.05:8
y = gaussrv (2,1.5,20000)
z = (hist(y,x) / (20000*0.05))
count (y, 2)
w = count (y, x)/20000
subplot(1,2,1)
plot (x, z)
subplot(1,2,1), axis([-4 8 0 0.4])
grid on
xlabel('x'); ylabel('pdf');
subplot(1,2,2)
plot(x, w)
subplot(1,2,2), axis([-4 8 0 1])
grid on
xlabel('x'); ylabel('cdf');
(3) 분석
연속함수이지만 x값을 이산형태로 줄 수밖에 없기 때문에 x값의 간격 매우 작게 두었다. x값을 더 작게 둘수록 매끄러운 그래프가 나오지만 샘플을 생성할 때는 흐트러지는 것을 볼 수 있었다. 샘플한 것을 살펴보면 pdf에 비해 CDF는 거의 흡사하다는 것을 볼 수 있다. 그 이유는 pdf에서는 x값 하나에 값이 들어가는 반면 CDF에서는 이것을 적분한 형태이기 때문이라고 생각이 든다.
샘플을 적게 생성할수록 pdf에서 양쪽 끝이 많이 변하는 모습을 살펴볼 수 있으며 샘플을 많이 생성하게 되면 원래의 그래프와 더 흡사한 형태가 나온다는 것을 확인할 수 있다.
- 가격3,000원
- 페이지수6페이지
- 등록일2008.04.22
- 저작시기2007.12
- 파일형식한글(hwp)
- 자료번호#462155

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글