

















































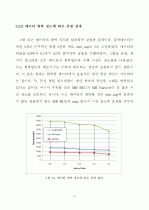
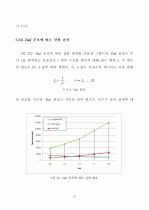




-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
해당 자료는 10페이지 까지만 미리보기를 제공합니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1.서 론 ······················································1
2.관련 연구 ···················································5
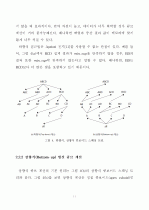
2.1 데이터 큐브와 빙산 큐브 ·····························5
2.2 빙산 큐브 계산 알고리즘 ·····························
2.2.1 하향식 빙산 큐브 계산 ························
2.2.2 상향식 빙산 큐브 계산 ························11
2.2.3 하향식과 상향식 통합 빙산 큐브 계산 ········13
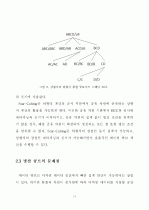
2.3 빙산 큐브의 문제점 ···································14
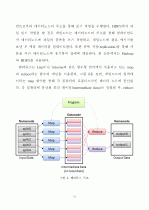
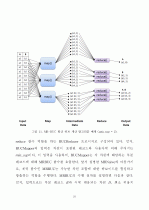
3.맵리듀스 프레임워크 ·······································16
3.1 맵리듀스 ···············································16
3.2 맵리듀스 활용 사례 ···································19
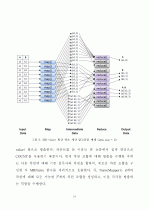
4.맵리듀스 기반 분산 병렬 빙산 큐브 계산 ·················22
4.1 MR-Naive 빙산 큐브 계산 ···························22
4.2 MR-BUC 빙산 큐브 계산 ····························27
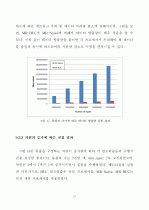
5.실험 및 분석 ···············································31
5.1 실험 환경 ·············································31
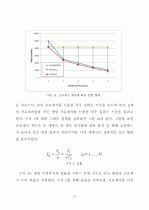
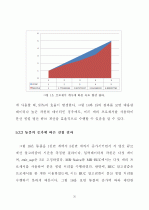
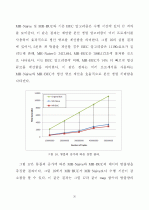
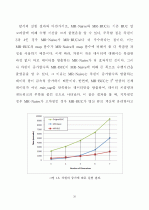
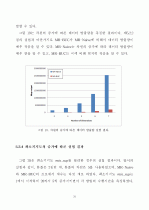
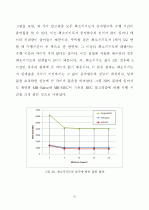
5.2 큐브 계산 성능 분석 ··································33
5.2.1 프로세서 개수에 따른 분석 ····················33
5.2.2 튜플 증가에 따른 분석 ························35
5.2.3 차원 증가에 따른 분석 ························37
5.2.4 최소지지도 증가에 따른 분석 ·················39
5.2.5 데이터 희박 정도에 따른 분석 ················41
5.2.6 Zipf 분포에 따른 분석 ·························42
6.결 론 ······················································44
참고 문헌 ···················································46
2.관련 연구 ···················································5
2.1 데이터 큐브와 빙산 큐브 ·····························5
2.2 빙산 큐브 계산 알고리즘 ·····························
2.2.1 하향식 빙산 큐브 계산 ························
2.2.2 상향식 빙산 큐브 계산 ························11
2.2.3 하향식과 상향식 통합 빙산 큐브 계산 ········13
2.3 빙산 큐브의 문제점 ···································14
3.맵리듀스 프레임워크 ·······································16
3.1 맵리듀스 ···············································16
3.2 맵리듀스 활용 사례 ···································19
4.맵리듀스 기반 분산 병렬 빙산 큐브 계산 ·················22
4.1 MR-Naive 빙산 큐브 계산 ···························22
4.2 MR-BUC 빙산 큐브 계산 ····························27
5.실험 및 분석 ···············································31
5.1 실험 환경 ·············································31
5.2 큐브 계산 성능 분석 ··································33
5.2.1 프로세서 개수에 따른 분석 ····················33
5.2.2 튜플 증가에 따른 분석 ························35
5.2.3 차원 증가에 따른 분석 ························37
5.2.4 최소지지도 증가에 따른 분석 ·················39
5.2.5 데이터 희박 정도에 따른 분석 ················41
5.2.6 Zipf 분포에 따른 분석 ·························42
6.결 론 ······················································44
참고 문헌 ···················································46
본문내용
. 24rd Int'l Conf. on Very Large Data Bases, pp. 299-310, Aug. 1998.
Bottom Up Computation of Iceberg Cube
using MapReduce Framework
Suan, Lee
Department of Computer Science
Graduate School, Kangwon National University
Abstract
Owing to advances in information and Web technologies, storing and analyzing a huge volume of data becomes an essential function of many real applications. For the efficient analysis on large databases, data cubes are widely used, and to solve the high computational cost problem of data cubes, iceberg cubes are introduced to handle only a small part of data cubes. The iceberg cube reduces storage space and CPU cost by concentrating the analysis on a specific part of a data cube, but it still causes severe storage and computation overhead due to a huge size of data. To solve this problem, we propose a distributed and parallel computation method that processes iceberg cubes on the top of the MapReduce framework. The MapReduce framework is the distributed and parallel computing technology that exploits many computer (or processor) connected through the high-speed network to solve a large size problem. In this paper we propose two iceberg cube computation algorithm, MR-Naive and MR-BUC, by using the MapReduce framework. MR-Naive applies the user-specified threshold, called min_sup, to the post-processing part of the MapReduce framework and works as follows: (1) it distributes all cuboids to the participating processors using the map function; (2) each processor computes the assigned cuboids; (3) the results of processors are aggregated to the final result by using the reduce function; and (4) if the final result exceeds min_sup, MR-Naive returns it. Next, MR-BUC is a distributed and parallel version of BUC(bottom up computation) and applies min_sup to the pre-processing part of the framework. MR-BUC works as follows: (1) using the given min_sup it filters original data through the partitioning and pruning process of BUC; (2) it distributes the filtered data to the participating processors using the map function; (3) each processors obtains its intermediate result; and (4) MR-BUC aggregates the intermediate result and returns the final result. Experimental results show that the performance of MR-Naive and MR-BUC increases as the number of processors increases, and they outperform the existing algorithms in most cases. In particular, MR-Naive outperforms MR-BUC in case of lower dimensionality while MR-BUC outperforms MR-Naive in case of higher dimensionality. This is because we use the map function in the pre-processing part of MR-Naive, but in the post-processing part of MR-BUC. Thus, to maximize the computation performance of iceberg cubes, users can choose MR-Naive or MR-BUC according to the data types. To our best knowledge, this is the first attempt to computing iceberg cubes by using the MapReduce framework, and we confirm that the framework efficiently processes the iceberg cubes in the distributed and parallel manner.
Bottom Up Computation of Iceberg Cube
using MapReduce Framework
Suan, Lee
Department of Computer Science
Graduate School, Kangwon National University
Abstract
Owing to advances in information and Web technologies, storing and analyzing a huge volume of data becomes an essential function of many real applications. For the efficient analysis on large databases, data cubes are widely used, and to solve the high computational cost problem of data cubes, iceberg cubes are introduced to handle only a small part of data cubes. The iceberg cube reduces storage space and CPU cost by concentrating the analysis on a specific part of a data cube, but it still causes severe storage and computation overhead due to a huge size of data. To solve this problem, we propose a distributed and parallel computation method that processes iceberg cubes on the top of the MapReduce framework. The MapReduce framework is the distributed and parallel computing technology that exploits many computer (or processor) connected through the high-speed network to solve a large size problem. In this paper we propose two iceberg cube computation algorithm, MR-Naive and MR-BUC, by using the MapReduce framework. MR-Naive applies the user-specified threshold, called min_sup, to the post-processing part of the MapReduce framework and works as follows: (1) it distributes all cuboids to the participating processors using the map function; (2) each processor computes the assigned cuboids; (3) the results of processors are aggregated to the final result by using the reduce function; and (4) if the final result exceeds min_sup, MR-Naive returns it. Next, MR-BUC is a distributed and parallel version of BUC(bottom up computation) and applies min_sup to the pre-processing part of the framework. MR-BUC works as follows: (1) using the given min_sup it filters original data through the partitioning and pruning process of BUC; (2) it distributes the filtered data to the participating processors using the map function; (3) each processors obtains its intermediate result; and (4) MR-BUC aggregates the intermediate result and returns the final result. Experimental results show that the performance of MR-Naive and MR-BUC increases as the number of processors increases, and they outperform the existing algorithms in most cases. In particular, MR-Naive outperforms MR-BUC in case of lower dimensionality while MR-BUC outperforms MR-Naive in case of higher dimensionality. This is because we use the map function in the pre-processing part of MR-Naive, but in the post-processing part of MR-BUC. Thus, to maximize the computation performance of iceberg cubes, users can choose MR-Naive or MR-BUC according to the data types. To our best knowledge, this is the first attempt to computing iceberg cubes by using the MapReduce framework, and we confirm that the framework efficiently processes the iceberg cubes in the distributed and parallel manner.
- 가격1,000원
- 페이지수55페이지
- 등록일2010.03.18
- 저작시기2009.1
- 파일형식한글(hwp)
- 자료번호#591182

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글