


















-
1
-
2
-
3
-
4
-
5
-
6
-
7
해당 자료는 2페이지 까지만 미리보기를 제공합니다.
2페이지 이후부터 다운로드 후 확인할 수 있습니다.
2페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1. COVID-19 관련 데이터 시각화의 국내외 사례 3개를 찾고 비교하여 정리하시오. (반드시 2022년 데이터가 포함된 사례를 사용할 것. 이미지를 캡처하여 한글이나 워드 파일에 첨부할 것. 이미지를 별도의 파일로 제출하지 말 것) (6점)
2. 한스 로즈링의 TED 강의(아래의 URL 이용)를 보고 데이터 시각화의 역할 등 느낀 점을 1페이지 이내로 정리하시오.(6점)
https://www.ted.com/talks/hans_rosling_let_my_dataset_change_your_mindset
(오른쪽 아래 메뉴에서 한글 자막 설정 가능)
3. R의 datarium 패키지에 내장된 marketing 데이터셋은 광고 미디어에 사용한 비용과 판매액의 데이터이다. facebook 컬럼은 facebook 광고비로 사용한 금액이고, sales 컬럼은 판매액이다. facebook을 x축, sales를 y축으로 하는 산점도를 그리시오. facebook을 독립변수(설명변수), sales를 종속변수(반응변수, 결과변수)로 하는 회귀직선을 산점도 위에 그리시오. 산점도의 제목으로 본인의 학번을 출력하시오. (9점) (힌트: datarium 패키지를 설치, 로드한 후 콘솔에 dat<-marketing을 입력하면 marketing 데이터셋이 dat에 저장된다)
4. 한국, 미국, 프랑스, 일본의 COVID-19 신규 확진자 수의 시간에 따른 추이를 데이터 시각화로 비교하고 향후 추이에 대해 의견 기술하라(데이터는 과제 작성일까지 올라와 있는 것을 이용하면 되며 학생별로 동일할 필요는 없음).(9점)
*데이터 소스: https://ourworldindata.org/covid-deaths 에서 “Our work belongs to everyone“이라 쓰여있는 네모 안의 .csv(아래 그림에서 빨간 네모)를 클릭하여 데이터를 다운로드 받아서 사용할 것.
*변수이름: iso_code가 각 국가를 나타낸다. (한국: KOR, 미국:USA, 프랑스: FRA, 일본: JPN)
new_cases가 신규 확진자 수를 나타낸다.
5. 참고문헌
2. 한스 로즈링의 TED 강의(아래의 URL 이용)를 보고 데이터 시각화의 역할 등 느낀 점을 1페이지 이내로 정리하시오.(6점)
https://www.ted.com/talks/hans_rosling_let_my_dataset_change_your_mindset
(오른쪽 아래 메뉴에서 한글 자막 설정 가능)
3. R의 datarium 패키지에 내장된 marketing 데이터셋은 광고 미디어에 사용한 비용과 판매액의 데이터이다. facebook 컬럼은 facebook 광고비로 사용한 금액이고, sales 컬럼은 판매액이다. facebook을 x축, sales를 y축으로 하는 산점도를 그리시오. facebook을 독립변수(설명변수), sales를 종속변수(반응변수, 결과변수)로 하는 회귀직선을 산점도 위에 그리시오. 산점도의 제목으로 본인의 학번을 출력하시오. (9점) (힌트: datarium 패키지를 설치, 로드한 후 콘솔에 dat<-marketing을 입력하면 marketing 데이터셋이 dat에 저장된다)
4. 한국, 미국, 프랑스, 일본의 COVID-19 신규 확진자 수의 시간에 따른 추이를 데이터 시각화로 비교하고 향후 추이에 대해 의견 기술하라(데이터는 과제 작성일까지 올라와 있는 것을 이용하면 되며 학생별로 동일할 필요는 없음).(9점)
*데이터 소스: https://ourworldindata.org/covid-deaths 에서 “Our work belongs to everyone“이라 쓰여있는 네모 안의 .csv(아래 그림에서 빨간 네모)를 클릭하여 데이터를 다운로드 받아서 사용할 것.
*변수이름: iso_code가 각 국가를 나타낸다. (한국: KOR, 미국:USA, 프랑스: FRA, 일본: JPN)
new_cases가 신규 확진자 수를 나타낸다.
5. 참고문헌
본문내용
ovid <- tidyr::spread(covid, iso_code, new_cases)
covid[is.na(covid)] <- 0 넓은 형태의 데이터로 변환하면서 생긴 결측치는 0으로 설정
library(xts)
covid.xts <- as.xts(covid[, c(\'KOR\', \'USA\', \'FRA\', \'JPN\')], order.by = covid$date)
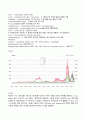
plot.xts(covid.xts, main=\'일별 확진자수\')
addLegend(\'top\', legend.names=c(\'KOR\', \'USA\', \'FRA\', \'JPN\'), lty=1, bg=\'white\', bty=\'o\') # 범례 추가
②결과
③설명
R에서는 시간 인덱스를 기반으로 데이터를 처리하기 위한 시계열 데이터 객체를 제공한다. ts, xts, tsibble 등이 그것이다. ts는 R에서 기본적으로 제공하는 시계열 데이터 타입으로 stats 패키지를 로딩한 후 사용가능하다. 이 패키지는 R 실행시 기본적으로 로딩되므로 바로 활용할 수 있다. 그러나 ts객체는 원본 데이터의 시간을 사용하지 않고, 인수(start, end, frequency)에 적당한 값을 주어 시작일, 종료일, 저장 주기를 설정하면 데이터의 시간을 설정한다.
xts는 extensibile time-series의 약자로 xts 패키지를 설치하고 로딩해야 활용할 수 있는 시계열 데이터 객체다. 따라서 위 코드에서는 원본 데이터의 시간을 사용할 수 없는 ts 대신 xts를 활용하여 시계열 도표를 작성한다. tsibble 객체는 tsibble 패키지를 통해 제공되는 시계열 데이터 객체로, 각 관찰값을 고유하게 식별할 수 있는 칼럼 혹은 칼럼의 집합인 key와 시간의 순서가 지정되는 index를 지정해야 한다.
코드에 대한 설명은 코드의 주석 참고하면 된다.
위 시계열 도표를 보면 각 국의 코로나 일별 확진자수는 국가마다 차이를 보이지만, 상승과 하락을 반복하는 주기성을 보여주고 있다. 특히 최근의 오미크론 변이의 유행으로 알 수 있듯이, 코로나 바이러스의 새로운 변이가 생기면 일정 기간이 지난 후에는 확진자수가 급증하는 양상을 보인다. 따라서 코로나 바이러스를 완전히 박멸하는 것은 현실적으로 불가능하므로, 새로운 변이가 생길 때마다 확진자수가 급증했다가 하락하는 추이가 지속될 것으로 예상한다. 결국 covid19 또한 환절기마다 찾아오는 감기처럼 주기적으로 경험하게 될 바이러스가 될 것으로 생각한다.
5. 참고문헌
이태림, 허명회, 이정진, 이긍희(2015). 데이터시각화. 출판문화원.
이기준(2021). 실전에서 바로 쓰는 시계열 데이터 처리와 분석 in R. 제이펍.
https://coronavirus.jhu.edu/map.html
https://coronavirus.jhu.edu/vaccines/international
https://www.bigdata-map.kr/covid19
https://www.gapminder.org/
https://ourworldindata.org/covid-deaths
covid[is.na(covid)] <- 0 넓은 형태의 데이터로 변환하면서 생긴 결측치는 0으로 설정
library(xts)
covid.xts <- as.xts(covid[, c(\'KOR\', \'USA\', \'FRA\', \'JPN\')], order.by = covid$date)
plot.xts(covid.xts, main=\'일별 확진자수\')
addLegend(\'top\', legend.names=c(\'KOR\', \'USA\', \'FRA\', \'JPN\'), lty=1, bg=\'white\', bty=\'o\') # 범례 추가
②결과
③설명
R에서는 시간 인덱스를 기반으로 데이터를 처리하기 위한 시계열 데이터 객체를 제공한다. ts, xts, tsibble 등이 그것이다. ts는 R에서 기본적으로 제공하는 시계열 데이터 타입으로 stats 패키지를 로딩한 후 사용가능하다. 이 패키지는 R 실행시 기본적으로 로딩되므로 바로 활용할 수 있다. 그러나 ts객체는 원본 데이터의 시간을 사용하지 않고, 인수(start, end, frequency)에 적당한 값을 주어 시작일, 종료일, 저장 주기를 설정하면 데이터의 시간을 설정한다.
xts는 extensibile time-series의 약자로 xts 패키지를 설치하고 로딩해야 활용할 수 있는 시계열 데이터 객체다. 따라서 위 코드에서는 원본 데이터의 시간을 사용할 수 없는 ts 대신 xts를 활용하여 시계열 도표를 작성한다. tsibble 객체는 tsibble 패키지를 통해 제공되는 시계열 데이터 객체로, 각 관찰값을 고유하게 식별할 수 있는 칼럼 혹은 칼럼의 집합인 key와 시간의 순서가 지정되는 index를 지정해야 한다.
코드에 대한 설명은 코드의 주석 참고하면 된다.
위 시계열 도표를 보면 각 국의 코로나 일별 확진자수는 국가마다 차이를 보이지만, 상승과 하락을 반복하는 주기성을 보여주고 있다. 특히 최근의 오미크론 변이의 유행으로 알 수 있듯이, 코로나 바이러스의 새로운 변이가 생기면 일정 기간이 지난 후에는 확진자수가 급증하는 양상을 보인다. 따라서 코로나 바이러스를 완전히 박멸하는 것은 현실적으로 불가능하므로, 새로운 변이가 생길 때마다 확진자수가 급증했다가 하락하는 추이가 지속될 것으로 예상한다. 결국 covid19 또한 환절기마다 찾아오는 감기처럼 주기적으로 경험하게 될 바이러스가 될 것으로 생각한다.
5. 참고문헌
이태림, 허명회, 이정진, 이긍희(2015). 데이터시각화. 출판문화원.
이기준(2021). 실전에서 바로 쓰는 시계열 데이터 처리와 분석 in R. 제이펍.
https://coronavirus.jhu.edu/map.html
https://coronavirus.jhu.edu/vaccines/international
https://www.bigdata-map.kr/covid19
https://www.gapminder.org/
https://ourworldindata.org/covid-deaths
키워드
추천자료
 생활법률 2021년 생활법률) 생활법률 A(남, 만 45세)와 B(여, 만 45세)는 같은 직장에 다니는...
생활법률 2021년 생활법률) 생활법률 A(남, 만 45세)와 B(여, 만 45세)는 같은 직장에 다니는...- [응급간호학] 2021년 출석수업대체과제물, 1. 기본소생술(BLS)의 과정, COVID-19 감염 또는 ...
- 인터넷과정보사회 2022년] 1.컴파일러와 인터프리터의 역할과 두 방식의 기능적 차이점 인터...
- 자원봉사론 2022년] 자원봉사란 무엇을 의미하는지 자원봉사의 주체와 대상 자원봉사론 최근 ...
- (방송통신대 통계조사방법론 중간과제물)1 유권자의 교육수준과 정치에 대한 관심 정도의 관...
- 가족교육론 2022년] 가족구성원인 한 명을 선정하여 면담을 통해 가족교육론 코로나19 상황에...
- 사회문제론 2022년) 다음 추천도서 중 한 권 이상을 읽고 감염병이 발생시키는 다양한 사회문...
- 가격6,000원
- 페이지수7페이지
- 등록일2022.04.16
- 저작시기2022.04
- 파일형식한글(hwp)
- 자료번호#1167227

본 자료는 최근 2주간 다운받은 회원이 없습니다.



소개글