






















-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
해당 자료는 3페이지 까지만 미리보기를 제공합니다.
3페이지 이후부터 다운로드 후 확인할 수 있습니다.
3페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1.object
2.theory & Algorithm
3.result analysis
4.afternote
5.reference
2.theory & Algorithm
3.result analysis
4.afternote
5.reference
본문내용
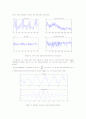
p the decision range by calculating average and made decision range value 1. Therefore in above figure average of my_voices is 20.7263 so decision range si 19.7263~21.7263. Other_voice(my frend's voice) is over range so my program distinguish it's not my voice and show '0' As we can see, all of my_voices(Final_Result) are in the accurate range(19.7263~21.7263) so if Other_voice is one of my_voices, my programe distinguish it's my voice and show '1'.
Figure 8. Equation of Cost function
Cost function is like above. In my simulation with my friend's voice, due to shortage of samples, so C=0. But If I have more samples I can calculate C more accurately.
There are some problems in my program. In this simulation I set up range is 1. But If I say too low voice or too high voice, my voice's pitch will be too high or too low. It will be over range and my system will distinguish it's not my voice. To solve this problem, I can try to say again like when I recorded or I can increase range value to 2 or 3 ... But If I do like the latter, there will be more error because I expand decision range. So when I say the password to open my vault, I have to say carefully.
Furthermore, in the simulation pitch period of all my voices are similar. But when I recorded one or two my voice, if I say too high voice or too low voice it affects the average of 10 of my voices - decision average goes up or goes down. It will be serious problem. To solve this problem, I can record carefully to say in similar tone or when I calculate average of 10 of my voices, I can except the highest pitch period and lowest pitch period - calculate average out of 8 voices. If I used GMM to distinguish voice, it will be better performance and it doesn't make serius problem like this but I couldn't make. In next project I will study much harder and try to make perfect solution.
: Afternote
Thanks for reading very very long report. Through this project, I could study a lot of speech recognition and learn and get interested in speech signal process. It will be helpful to study in graduate school and I learn make constant efforts to the impossible like problem.
: Reference
[1] J. W. Picone, "Signal modeling techniques in speech recognition," Proc. IEEE, vol. 8, no. 9, pp. 1215-1247, Sept. 1993.
[2] D. O'Shaughnessy, Speech Communication: Human and Machine, 2nd ed. Addison-Wesley.
[3] J. B. Allen, "Cochlear modeling," IEEE ASSP Magazine, vol. 3, no. 3, pp. 3-29, Sept. 1985.
[4] S. B. Davis and P. Mermelstein, "Comparison of parametric representations of monosyllabic word recognition in continuously spoken sentences," IEEE Trans. ASSP, vo. 28, no. 4, pp. 357-366, Aug. 1980.
[5] H. Hermansky, et al., "RASTA-PLP speech analysis technique," ICASSP'92.
[6] J.-C. Junqua and J.-P. Haton, Robustness in automatic speech recognition, Kluwer Academic Publishers, 1996.
[7] 음성인식 , 한양대학교 출판부
[8] 한학용 , 패턴인식개론 , 한빛미디어
[9] 한진수 , 음성 신호 처리 , 오성미디어
[10] Google search by "Speech recognition", "LPC", "GMM", "MFCC" ...
Figure 8. Equation of Cost function
Cost function is like above. In my simulation with my friend's voice, due to shortage of samples, so C=0. But If I have more samples I can calculate C more accurately.
There are some problems in my program. In this simulation I set up range is 1. But If I say too low voice or too high voice, my voice's pitch will be too high or too low. It will be over range and my system will distinguish it's not my voice. To solve this problem, I can try to say again like when I recorded or I can increase range value to 2 or 3 ... But If I do like the latter, there will be more error because I expand decision range. So when I say the password to open my vault, I have to say carefully.
Furthermore, in the simulation pitch period of all my voices are similar. But when I recorded one or two my voice, if I say too high voice or too low voice it affects the average of 10 of my voices - decision average goes up or goes down. It will be serious problem. To solve this problem, I can record carefully to say in similar tone or when I calculate average of 10 of my voices, I can except the highest pitch period and lowest pitch period - calculate average out of 8 voices. If I used GMM to distinguish voice, it will be better performance and it doesn't make serius problem like this but I couldn't make. In next project I will study much harder and try to make perfect solution.
: Afternote
Thanks for reading very very long report. Through this project, I could study a lot of speech recognition and learn and get interested in speech signal process. It will be helpful to study in graduate school and I learn make constant efforts to the impossible like problem.
: Reference
[1] J. W. Picone, "Signal modeling techniques in speech recognition," Proc. IEEE, vol. 8, no. 9, pp. 1215-1247, Sept. 1993.
[2] D. O'Shaughnessy, Speech Communication: Human and Machine, 2nd ed. Addison-Wesley.
[3] J. B. Allen, "Cochlear modeling," IEEE ASSP Magazine, vol. 3, no. 3, pp. 3-29, Sept. 1985.
[4] S. B. Davis and P. Mermelstein, "Comparison of parametric representations of monosyllabic word recognition in continuously spoken sentences," IEEE Trans. ASSP, vo. 28, no. 4, pp. 357-366, Aug. 1980.
[5] H. Hermansky, et al., "RASTA-PLP speech analysis technique," ICASSP'92.
[6] J.-C. Junqua and J.-P. Haton, Robustness in automatic speech recognition, Kluwer Academic Publishers, 1996.
[7] 음성인식 , 한양대학교 출판부
[8] 한학용 , 패턴인식개론 , 한빛미디어
[9] 한진수 , 음성 신호 처리 , 오성미디어
[10] Google search by "Speech recognition", "LPC", "GMM", "MFCC" ...
추천자료
 정보공학 기술과 가상기업, 정보 기술이 조직에 미치는 영향
정보공학 기술과 가상기업, 정보 기술이 조직에 미치는 영향- 한국 IBM의 성공사례
- 유아교육기관의 컴퓨터 환경
- 유비쿼터스의 적용 사례 조사
- 유비쿼터스정의와 국내외동향
- 노자, 자연으로 돌아가자
- 피부를 입는다 “스마트웨어”
- 조립피씨 레포트
- 웨어러블 컴퓨터에대한 자세한 조사
- 언어지도-기말교안
- 구글 크롬(google chrome)의 주요기능, 특징, 전략분석, 소비자선호도, 위협과 기회요인
- [정보기술정책, IT정책]정보기술정책(IT정책)과 정책평가요소, 기술이전정책, 정보기술정책(I...
 (웨어러블 컴퓨터 ) 웨어러블 컴퓨터 기술의 이해 및 적용사례 [Wearable Computer Technology]
(웨어러블 컴퓨터 ) 웨어러블 컴퓨터 기술의 이해 및 적용사례 [Wearable Computer Technology]
- 가격5,000원
- 페이지수11페이지
- 등록일2010.12.23
- 저작시기2010.11
- 파일형식한글(hwp)
- 자료번호#644555

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글