
































































-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
해당 자료는 10페이지 까지만 미리보기를 제공합니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
의사결정나무분석 (Decision Tree)
로지스틱회귀분석 (Logistic Regression)
신경망분석 (Neural Network)
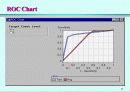
예측모형의 평가 (Assessment)
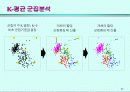
군집분석 (Clustering)
연관성분석 (Association Analysis)
로지스틱회귀분석 (Logistic Regression)
신경망분석 (Neural Network)
예측모형의 평가 (Assessment)
군집분석 (Clustering)
연관성분석 (Association Analysis)
본문내용
1. Data Mining Models
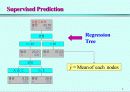
Supervised Modeling
Supervised Prediction
Target Variable : Continuous (or Discrete)
Regression Analysis, Regression Tree, Neural Network
Supervised Classification
Target Variable : Discrete
Discrimination Analysis, Classification Tree, Neural Network
Unsupervised Modeling
No Target Variable
Clustering, SOM(Kohonen Network), Association Rule
2. 의사결정나무분석의 과정
의사결정나무의 형성(Growing the Tree)
분리기준(Splitting Criteria),
정지규칙(Stopping Rule)
가지치기(Pruning)
타당성 평가(Validation)
이익(Gain), 위험(Risk), 비용(Cost)
분류 및 예측(Classification, Prediction)
3. 분리기준(Splitting Criteria)
이산형 목표변수(categorical target)
카이제곱 통계량(Chi-Square statistic)
지니 지수(Gini index)
엔트로피 지수(Entropy index)
연속형 목표변수(continous target)
F 통계량
분산의 감소량(Variance reduction)
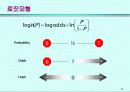
4. 로지스틱회귀분석의 특징
장점
친밀성 (Familiarity)
실제성 (Feasibility)
해석상의 편리 (Interpretability)
단점
부적절하거나 불필요한 입력변수 : 변수선택방법 사용
선형성 : 다항회귀모형, 의사결정나무분석, 신경망분석 등 사용
교호작용의 결여 : 다항회귀모형, 의사결정나무분석 등 사용
명목형 변수 : 가변수(dummy variable) 사용
결측값 : 대체(imputation)
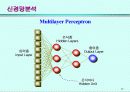
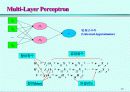
5. 신경망의 구조
입력층
각 입력변수에 대응되는 마디들로 구성되어 있다. 명목형(nominal) 변수에 대해서는 각 수준에 대응하는 입력마디를 가지게 되는데, 이는 통계적 선형모형에서 가변수(dummy variable)를 사용하는 것과 같다.
은닉층
여러 개의 은닉마디로 구성되어 있다. 입력층으로부터 전달되는 변수값들의 선형결합(linear combination)을 비선형함수(nonlinear function)로 처리하여 출력층 또는 다른 은닉층에 전달한다.
출력층
목표변수(target)에 대응하는 마디들을 갖는다. 여러 개의 목표변수 또는 세 개 이상의 수준을 가지는 명목형 목표변수가 있을 경우에는 여러 개의 출력마디들이 존재한다.
6. 최적화와 비수렴성
반복적 최적화
1) 각 계수에 대해서 임의의 초기값을 부여한다.
2) 새로운 값 = 이전 값 + 수정값
3) 수렴할 때까지(즉, 이전 값과 새로운 값의 차이가 거의 없을 때까지) 반복적으로 수행한다.
최적화(Training) 방법
backpropagation: 신경망
Levenberg-Marquardt
quasi-Newton
conjugate- gradient
Supervised Modeling
Supervised Prediction
Target Variable : Continuous (or Discrete)
Regression Analysis, Regression Tree, Neural Network
Supervised Classification
Target Variable : Discrete
Discrimination Analysis, Classification Tree, Neural Network
Unsupervised Modeling
No Target Variable
Clustering, SOM(Kohonen Network), Association Rule
2. 의사결정나무분석의 과정
의사결정나무의 형성(Growing the Tree)
분리기준(Splitting Criteria),
정지규칙(Stopping Rule)
가지치기(Pruning)
타당성 평가(Validation)
이익(Gain), 위험(Risk), 비용(Cost)
분류 및 예측(Classification, Prediction)
3. 분리기준(Splitting Criteria)
이산형 목표변수(categorical target)
카이제곱 통계량(Chi-Square statistic)
지니 지수(Gini index)
엔트로피 지수(Entropy index)
연속형 목표변수(continous target)
F 통계량
분산의 감소량(Variance reduction)
4. 로지스틱회귀분석의 특징
장점
친밀성 (Familiarity)
실제성 (Feasibility)
해석상의 편리 (Interpretability)
단점
부적절하거나 불필요한 입력변수 : 변수선택방법 사용
선형성 : 다항회귀모형, 의사결정나무분석, 신경망분석 등 사용
교호작용의 결여 : 다항회귀모형, 의사결정나무분석 등 사용
명목형 변수 : 가변수(dummy variable) 사용
결측값 : 대체(imputation)
5. 신경망의 구조
입력층
각 입력변수에 대응되는 마디들로 구성되어 있다. 명목형(nominal) 변수에 대해서는 각 수준에 대응하는 입력마디를 가지게 되는데, 이는 통계적 선형모형에서 가변수(dummy variable)를 사용하는 것과 같다.
은닉층
여러 개의 은닉마디로 구성되어 있다. 입력층으로부터 전달되는 변수값들의 선형결합(linear combination)을 비선형함수(nonlinear function)로 처리하여 출력층 또는 다른 은닉층에 전달한다.
출력층
목표변수(target)에 대응하는 마디들을 갖는다. 여러 개의 목표변수 또는 세 개 이상의 수준을 가지는 명목형 목표변수가 있을 경우에는 여러 개의 출력마디들이 존재한다.
6. 최적화와 비수렴성
반복적 최적화
1) 각 계수에 대해서 임의의 초기값을 부여한다.
2) 새로운 값 = 이전 값 + 수정값
3) 수렴할 때까지(즉, 이전 값과 새로운 값의 차이가 거의 없을 때까지) 반복적으로 수행한다.
최적화(Training) 방법
backpropagation: 신경망
Levenberg-Marquardt
quasi-Newton
conjugate- gradient
추천자료
 사례를 통한 CRM 구축방안
사례를 통한 CRM 구축방안- 고객관계관리(CRM)시스템 구축 및 활용실태
- 의사결정지원시스템(DSS Decision Support System)사례
- 고객 관계 관리CRM (Customer Relationship Mana gement)논문
- 정부기관경영평가시스템의회고와발전방안
- 고객관계관리
- 성공적인 CRM(고객관계관리)전략수립 방안
- 경영학콘서트 독후감-요약 및 느낀점
- 고객만족과 CRM의 실천방안에 대해서 서술
- 경영정보시스템
- selc 인강 CRM 고객관계관리전략 (01강~15강)
- 의료정보학 중요 정리 - 전자 의무 기록, 병원정보시스템(HIS), 보건의료정보 표준화, 의료영...
- CRM(Customer Relationship Management : 고객관계관리) 개요와 사례 보고서 (CRM 정의·개념·...
 selc 고객관계관리 기말자료 족보 (09주차~15주차)
selc 고객관계관리 기말자료 족보 (09주차~15주차)
- 가격3,000원
- 페이지수62페이지
- 등록일2006.03.05
- 저작시기2006.03
- 파일형식파워포인트(ppt)
- 자료번호#338548

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글