






































-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
해당 자료는 10페이지 까지만 미리보기를 제공합니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.
10페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
*금융기업 정보를 WEKA프로그램으로 다양하게 분석
1. 연관분석기법
2. 군집화기법
3. 이산화기법
a.weka 프로그램으로 각각의 기법들을 적용
ㄱ. 연관분석기법으로 분석하는 과정을 캡쳐
ㄴ. 연관분석기법을 통한 결과를 캡쳐
ㄷ. 결과된 다양한 데이터를 분석 내용물 도출해냄
ㄹ. 군집화기법으로 분석하는 과정을 캡쳐
ㅁ. 군집화기법으로 도출된 결과를 캡쳐
ㅇ. 군집화기법으로 도출된 결과내용을 분석함
.
.
.
.
.
(이산화기법도 위와 동일하게 함)
4.각각의 기법들을 결합하여 분석
A.도표,그래프,알고리즘등을 캡쳐(성별,직업,나이,거주지,소득수준...)
여러가지 다양한 요소들을 반영하여 각각 캡쳐
B.위 자료들을 통해서 분석
C.분석된 자료들을 통해서 결과를 도출 내용 설명
.
.
.
.
.
결론:weka프로그램을 통해 금융기관 고객들에 대한 다양한 정보를 얻기 위한 과정이다. 이러한 정보를 얻기위해 여러가지 사항들(성별,직업,나이,거주지,소득수준...)를 분석해야하며 각각의 분석된 자료를 통해서 데이터를 관리한다.
1. 연관분석기법
2. 군집화기법
3. 이산화기법
a.weka 프로그램으로 각각의 기법들을 적용
ㄱ. 연관분석기법으로 분석하는 과정을 캡쳐
ㄴ. 연관분석기법을 통한 결과를 캡쳐
ㄷ. 결과된 다양한 데이터를 분석 내용물 도출해냄
ㄹ. 군집화기법으로 분석하는 과정을 캡쳐
ㅁ. 군집화기법으로 도출된 결과를 캡쳐
ㅇ. 군집화기법으로 도출된 결과내용을 분석함
.
.
.
.
.
(이산화기법도 위와 동일하게 함)
4.각각의 기법들을 결합하여 분석
A.도표,그래프,알고리즘등을 캡쳐(성별,직업,나이,거주지,소득수준...)
여러가지 다양한 요소들을 반영하여 각각 캡쳐
B.위 자료들을 통해서 분석
C.분석된 자료들을 통해서 결과를 도출 내용 설명
.
.
.
.
.
결론:weka프로그램을 통해 금융기관 고객들에 대한 다양한 정보를 얻기 위한 과정이다. 이러한 정보를 얻기위해 여러가지 사항들(성별,직업,나이,거주지,소득수준...)를 분석해야하며 각각의 분석된 자료를 통해서 데이터를 관리한다.
본문내용
<-- No class
Cluster 57 <-- No class
Cluster 59 <-- No class
Cluster 61 <-- No class
Cluster 62 <-- No class
Cluster 63 <-- No class
Cluster 64 <-- No class
Cluster 67 <-- No class
Cluster 70 <-- No class
Cluster 71 <-- No class
Cluster 72 <-- No class
Cluster 74 <-- No class
Cluster 76 <-- No class
Cluster 77 <-- No class
Cluster 80 <-- No class
Cluster 81 <-- No class
Cluster 82 <-- No class
Cluster 83 <-- No class
Cluster 86 <-- No class
Cluster 87 <-- No class
Cluster 88 <-- No class
Cluster 90 <-- No class
Cluster 91 <-- No class
Cluster 94 <-- No class
Cluster 98 <-- No class
Cluster 100 <-- No class
Cluster 101 <-- No class
Cluster 103 <-- No class
Cluster 104 <-- No class
Cluster 105 <-- No class
Cluster 106 <-- No class
Cluster 108 <-- No class
Cluster 111 <-- No class
Cluster 114 <-- No class
Cluster 115 <-- No class
Cluster 117 <-- No class
Cluster 118 <-- No class
Cluster 119 <-- No class
Cluster 120 <-- No class
Cluster 122 <-- No class
Cluster 123 <-- No class
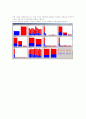
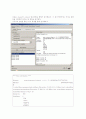
Incorrectly clustered instances :264.0 88 %
대도시 중소도시 산간도시로 나뉘어 각종 트리 구조와 잎구조로 나뉘어 분석이 되었다.
각각의 도시들의 인구수에 비례해서 이탈의 성향을 보인다. 인구수가 가장 많은 대도시 같은 경우 이탈하는 고객의 숫자가 가장 많으며 그다음 중소도시 산간도시 순을 이룬다.
적중률은 88%이다.
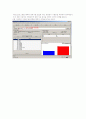
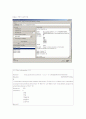
=== Run information ===
Scheme: weka.associations.Apriori -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.1 -S -1.0
Relation: 전화이탈자(WEKA용)-weka.filters.unsupervised.attribute.Discretize-F-B10-M-1.0-Rfirst-last-weka.filters.unsupervised.attribute.Discretize-F-B10-M-1.0-Rfirst-last
Instances: 300
Attributes: 11
성별
나이
직업
거주지
지불유형
납입종류
사용총액
기본요금
부가서비스요금
사용기간
고객구분
=== Associator model (full training set) ===
Apriori
=======
Minimum support: 0.5
Minimum metric: 0.9
Number of cycles performed: 10
Generated sets of large itemsets:
Size of set of large itemsets L(1): 10
Size of set of large itemsets L(2): 6
Size of set of large itemsets L(3): 1
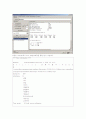
Best rules found:
1. 사용총액='(-inf-82]' 176 ==> 기본요금='(-inf-82]' 부가서비스요금='(-inf-15]' 176 conf:(1)
2. 기본요금='(-inf-82]' 176 ==> 사용총액='(-inf-82]' 부가서비스요금='(-inf-15]' 176 conf:(1)
3. 사용총액='(-inf-82]' 기본요금='(-inf-82]' 176 ==> 부가서비스요금='(-inf-15]' 176 conf:(1)
4. 사용총액='(-inf-82]' 부가서비스요금='(-inf-15]' 176 ==> 기본요금='(-inf-82]' 176 conf:(1)
5. 기본요금='(-inf-82]' 부가서비스요금='(-inf-15]' 176 ==> 사용총액='(-inf-82]' 176 conf:(1)
6. 기본요금='(-inf-82]' 176 ==> 부가서비스요금='(-inf-15]' 176 conf:(1)
7. 사용총액='(-inf-82]' 176 ==> 부가서비스요금='(-inf-15]' 176 conf:(1)
8. 사용총액='(-inf-82]' 176 ==> 기본요금='(-inf-82]' 176 conf:(1)
9. 기본요금='(-inf-82]' 176 ==> 사용총액='(-inf-82]' 176 conf:(1)
10. 납입종류=기타 161 ==> 직업=학생 151 conf:(0.94)
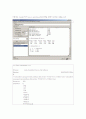
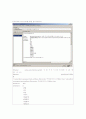
마지막으로 Associate를 통한 분석기법이다.
위 연관 분석 모형에서는 요금에 따른 연관 규칙성을 나타내 준다. 기본요금과 사용총액 부과서비스 요금에 따른 이탈자와 유지자의 연관성을 나타내준다.
다양한 기법과 알고리즘으로 분석 처리하면 여러 가지 분석 상황이 도출된다. 각각의 항목들이 서로 연관성을 가지고 유지와 이탈고객등을 분석해 내는데 성별에 따라서는 나이 직업 사용총액 기본요금 부가서비스 요금등에서 이탈에 대한 변화현상을 나타내며 나이에 따라서는 직업 납입종류 기본요금에 따라 다르게 분석되어진다.
즉 각각의 항목 하나하나를 분석해서 가장 연관성 있는 항목들이 도출 되는데 그 결과를 바탕으로 고객관리를 한다.
지불유형에 따른 고객관리를 할려면 거주지와 기본요금에 중점을 두어야 한다.
납입종류에 따른 고객관리를 할려면 나이 직업 기본요금등에 중점을 두어야 한다.
연관부석을 통해 가장 관련성 깊은 속성들에 대한 도출 값들이기 때문이다.
Cluster 57 <-- No class
Cluster 59 <-- No class
Cluster 61 <-- No class
Cluster 62 <-- No class
Cluster 63 <-- No class
Cluster 64 <-- No class
Cluster 67 <-- No class
Cluster 70 <-- No class
Cluster 71 <-- No class
Cluster 72 <-- No class
Cluster 74 <-- No class
Cluster 76 <-- No class
Cluster 77 <-- No class
Cluster 80 <-- No class
Cluster 81 <-- No class
Cluster 82 <-- No class
Cluster 83 <-- No class
Cluster 86 <-- No class
Cluster 87 <-- No class
Cluster 88 <-- No class
Cluster 90 <-- No class
Cluster 91 <-- No class
Cluster 94 <-- No class
Cluster 98 <-- No class
Cluster 100 <-- No class
Cluster 101 <-- No class
Cluster 103 <-- No class
Cluster 104 <-- No class
Cluster 105 <-- No class
Cluster 106 <-- No class
Cluster 108 <-- No class
Cluster 111 <-- No class
Cluster 114 <-- No class
Cluster 115 <-- No class
Cluster 117 <-- No class
Cluster 118 <-- No class
Cluster 119 <-- No class
Cluster 120 <-- No class
Cluster 122 <-- No class
Cluster 123 <-- No class
Incorrectly clustered instances :264.0 88 %
대도시 중소도시 산간도시로 나뉘어 각종 트리 구조와 잎구조로 나뉘어 분석이 되었다.
각각의 도시들의 인구수에 비례해서 이탈의 성향을 보인다. 인구수가 가장 많은 대도시 같은 경우 이탈하는 고객의 숫자가 가장 많으며 그다음 중소도시 산간도시 순을 이룬다.
적중률은 88%이다.
=== Run information ===
Scheme: weka.associations.Apriori -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.1 -S -1.0
Relation: 전화이탈자(WEKA용)-weka.filters.unsupervised.attribute.Discretize-F-B10-M-1.0-Rfirst-last-weka.filters.unsupervised.attribute.Discretize-F-B10-M-1.0-Rfirst-last
Instances: 300
Attributes: 11
성별
나이
직업
거주지
지불유형
납입종류
사용총액
기본요금
부가서비스요금
사용기간
고객구분
=== Associator model (full training set) ===
Apriori
=======
Minimum support: 0.5
Minimum metric
Number of cycles performed: 10
Generated sets of large itemsets:
Size of set of large itemsets L(1): 10
Size of set of large itemsets L(2): 6
Size of set of large itemsets L(3): 1
Best rules found:
1. 사용총액='(-inf-82]' 176 ==> 기본요금='(-inf-82]' 부가서비스요금='(-inf-15]' 176 conf:(1)
2. 기본요금='(-inf-82]' 176 ==> 사용총액='(-inf-82]' 부가서비스요금='(-inf-15]' 176 conf:(1)
3. 사용총액='(-inf-82]' 기본요금='(-inf-82]' 176 ==> 부가서비스요금='(-inf-15]' 176 conf:(1)
4. 사용총액='(-inf-82]' 부가서비스요금='(-inf-15]' 176 ==> 기본요금='(-inf-82]' 176 conf:(1)
5. 기본요금='(-inf-82]' 부가서비스요금='(-inf-15]' 176 ==> 사용총액='(-inf-82]' 176 conf:(1)
6. 기본요금='(-inf-82]' 176 ==> 부가서비스요금='(-inf-15]' 176 conf:(1)
7. 사용총액='(-inf-82]' 176 ==> 부가서비스요금='(-inf-15]' 176 conf:(1)
8. 사용총액='(-inf-82]' 176 ==> 기본요금='(-inf-82]' 176 conf:(1)
9. 기본요금='(-inf-82]' 176 ==> 사용총액='(-inf-82]' 176 conf:(1)
10. 납입종류=기타 161 ==> 직업=학생 151 conf:(0.94)
마지막으로 Associate를 통한 분석기법이다.
위 연관 분석 모형에서는 요금에 따른 연관 규칙성을 나타내 준다. 기본요금과 사용총액 부과서비스 요금에 따른 이탈자와 유지자의 연관성을 나타내준다.
다양한 기법과 알고리즘으로 분석 처리하면 여러 가지 분석 상황이 도출된다. 각각의 항목들이 서로 연관성을 가지고 유지와 이탈고객등을 분석해 내는데 성별에 따라서는 나이 직업 사용총액 기본요금 부가서비스 요금등에서 이탈에 대한 변화현상을 나타내며 나이에 따라서는 직업 납입종류 기본요금에 따라 다르게 분석되어진다.
즉 각각의 항목 하나하나를 분석해서 가장 연관성 있는 항목들이 도출 되는데 그 결과를 바탕으로 고객관리를 한다.
지불유형에 따른 고객관리를 할려면 거주지와 기본요금에 중점을 두어야 한다.
납입종류에 따른 고객관리를 할려면 나이 직업 기본요금등에 중점을 두어야 한다.
연관부석을 통해 가장 관련성 깊은 속성들에 대한 도출 값들이기 때문이다.
추천자료
 (보험)데이터베이스 보험 마케팅
(보험)데이터베이스 보험 마케팅- DBMS/DB MARKETING - 데이터베이스 마케팅의 이해와 적용사례에 대한 보고서
- 멀티미디어 데이터의 처리 - 7장 연습문제 풀이 -
- DB마케팅을 통한 의류브랜드의 데이터 분석
- <마케팅> 데이터 베이스 마케팅
 틈새라면 수요, 통계, 경제성, 데이터베이스
틈새라면 수요, 통계, 경제성, 데이터베이스- 멀티미디어 데이터 압축기술
 데이터베이스 회복
데이터베이스 회복 - 데이터베이스 설계
- 데이터 웨어하우스와 OLAP 기술
- [KORMARC]KORMARC(한국문헌자동화목록법)의 설계, KORMARC(한국문헌자동화목록법)의 데이터처...
- Wal-mart의 데이터웨어하우징
- 정보통신 - 빅 데이터 (Big data)에 관해서
- 가격3,000원
- 페이지수33페이지
- 등록일2006.08.30
- 저작시기2006.3
- 파일형식한글(hwp)
- 자료번호#362555

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글