
























-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
해당 자료는 4페이지 까지만 미리보기를 제공합니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.
4페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
7.1 주 메모리 기술
7.2 80x86 프로세서의 읽기 및 쓰기 버스 사이클
7.3 80x86의 SRAM 인터페이스 예
7.4 주소 디코딩 기법
7.5 DRAM의 사양과 타이밍
7.2 80x86 프로세서의 읽기 및 쓰기 버스 사이클
7.3 80x86의 SRAM 인터페이스 예
7.4 주소 디코딩 기법
7.5 DRAM의 사양과 타이밍
본문내용
두 리프레시 하는 외부 하드웨어가 요구된다. 구현이 어렵다.
전
(CBR;
before
) 리프레시 [그림 7-58 (b)]
: CBR 기법에서는
클럭이 0으로 내려가기 전에
클럭을 활성화시킨다.
그러면 DRAM은 외부 하드웨어 도움 없이 행 주소를 생성하고 그 행의 모든 셀을 리프레시 한다.
:
를 0으로 유지하고,
클럭을 사용하면 행 주소가 순서에 따라 내부적으로 생성되어 리프레시 한다.
자가 리프레시 (Self-refresh)
: 자가 리프레시는 CBR 리프레시와 동일하나,
와
가 최소 10㎲ 동안 0을 유지한다.
그러면 동일 칩 발진기가 자동적으로 리프레시 주소를 생성한다.
이 모드에서 나오면 완전히 리프레시 되는 것을 보장하기 위하여 버스트 리프레시를 수행하여야 한다.
리프레시 사이클의 분배
1. 버스트 리프레시 : 프로세서가 대기 상태로 들어가고 모든 행이 한번의 버스트로 리프레시 된다.
2. 분배 리프레시 : 전체 리프레시 주기에 걸쳐 리프레시 사이클을 분배할 수 있다. 대부분 이 기법 채택
3. 은닉 리프레시 : 정상적인 메모리 액세스 후
클럭을 0으로 유지하면 데이터가 출력 핀에 유지된다.
이제 DRAM이 내부적으로 행 주소를 증가시키므로, 몇 번이든지
클럭을 적용한다.
5. DRAM 제어기
PC/XT
: IBM PC와 XT는 개별 논리소자를 사용하여 DRAM을 8088 프로세서에 인터페이스 한다.
: 15㎲ 마다 시스템의 타이머에 의하여 시작하는
-only 분배 기법으로 리프레시 한다.
그러면 dummy 읽기 사이클이 DMA 제어기(8237)에 의하여 수행된다. (프로세서 시간의 5% 정도)
최신 컴퓨터
: PC/XT에서의 DMA 제어기, 시스템 타이머, 주소 디코딩 회로 등을 조합한 칩셋(chipset)으로 대체 되었다.
참고 도면
<부록> DRAM의 Refresh에 대한 검토
교재 332페이지 중간
리프레시(refresh). 저장 노드는 완벽하지 못하여 시간이 지나면 방전되는 것이 DRAM의 가장 큰 단점이라는 것을 잘 알고 있을 것이다. 이 때문에 리프레시 동작이 필요하게된다. 리프레시 동작이란 전하를 감지하여 증폭한 다음 다시 기록하는 것을 말한다. DRAM에 따라 차이는 있지만, 리프레시 작업은 각 메모리 셀에 대하여 1∼16 ms마다 한번씩 수행하여야 한다.
리프레시 작업은 생각하는 것보다 쉽게 구현할 수 있다. 그림 7.9를 보면 SRAM의 행이 엑세스될 때마다, 프리차지 회로가 캐패시터에 저장된 전하를 회복시킴을 알 수 있다. 따라서 단순히 메모리 내용을 읽거나 쓰기만 하여도 메모리가 리프레시 된다.
교재 391 페이지 아래
7.5.4 리프레시
7.1절에서 언급한 것처럼, 동적 RAM의 저장 셀은 캐패시터이다. 이 캐패시터는 결국 전하를 잃게 되므로, 각 셀의 전하는 주기적으로 다시 써야한다. 대개 이 작업은 15.625 ㎲ 마다 한번씩 행을 차례대로 엑세스함으로써 이루어진다. 그러므로 n비트의 행 주소를 가지고 있는 DRAM의 리프레시 주기(리프레시 없이 한 행이 버틸 수 있는 최대 시간)는,
리프레시 주기 = 2n x 15.625㎲ 이다.
예제 7.14
풀이 : 리프레시 주기는 32 ms이다
이 문제 풀이와 아래에 보인바와 같은 위 332 페이지의 설명의 상호 관계는 무엇일까요...
DRAM에 따라 차이는 있지만, 리프레시 작업은 각 메모리 셀에 대하여 1∼16 ms마다 한번씩 수행하여야 한다.
다른 교재를 참고하면 다음과 같습니다. \"인텔 마이크로프로세서\", Barry B. Brey저, 권갑현 공역
제4장 메모리 인터페이스
4-7 DRAM
◈ DRAM에 대한 재 고찰
4-1절에서 언급하였듯이 DRAM은 단지 2-4ms 정도 동안만 데이터를 유지하며, 주소 입력의 멀티플렉싱을 필요로 한다. 이미 4-1절에서 주소 멀티플렉싱에 관하여 살펴보았으므로, 여기서는 리프레시 동안 일어나는 DRAM의 동작에 관하여 자세히 살펴볼 것이다.
앞에서 언급하였듯이, DRAM은 짧은 주기 안에 자신의 전하를 잃어버리는 캐패시터 내에 데이터를 저장하기 때문에, 주기적으로 리프레시를 해주어야한다. DRAM을 리프레시 해주기 위해서는, 메모리 내의 내용이 주기적으로 읽혀지거나 써 넣어져야한다. 모든 읽기 또는 쓰기 동작은 자동적으로 DRAM의 전체를 리프레시 해준다. 리프레시 되는 비트의 수는 메모리 소자의 크기와 내부 조직에 따라 다르게 된다.
리프레시 사이클(refresh cycle)은 읽기, 쓰기, 혹은 데이터를 읽지도 쓰지도 하지 않는 특수한 리프레시 사이클에 의해 수행된다. 리프레시 사이클은 완전히 DRAM의 내부적인 동작이며, 시스템 내의 다른 메모리 소자들이 작동 중인 동안에 수행된다. 이와 같은 형태의 리프레시를 은닉 리프레시(hidden refresh), 투명 리프레시(transparent refresh) 혹은 사이클 훔치기(cycle stealing)라고 부른다.
<중략>
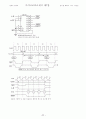
그림 4-39는
전용 리프레시 사이클을 위한 타이밍을 보여주고 있다.
와 쓰기 혹은 읽기 간의 주된 차이점은 이 사이클에서는 리프레시 주소만 인가된다는 점이다. 이 주소는 대개 7 비트 또는 8비트 2진 카운터에 의해 얻어진다. 카운터의 크기는 리프레시 되는 DRAM의 형태에 의해 결정된다. 리프레시 카운터는 각각의 리프레시 사이클의 끝에서 증가되며, 그 결과 모든 행들이 DRAM의 형태에 따라 2 또는 4ms만에 리프레시 된다.
256K x 1 DRAM에서처럼 4 ms 내에 256K 개의 행이 리프레시 되어야 한다면, 리프레시 사이클은 적어도 15.6 ㎲ 마다 한번씩 활성화 되어야한다. 예를 들어, 5 MHz 클럭으로 동작하는 8086/8088의 경우에는 읽기 또는 쓰기 동작에 800ns가 걸린다. DRAM이 매 15.6 ㎲ 마다 리프레시 사이클을 가져야 하므로, 매 19회의 메모리 읽기 또는 쓰기 동작마다 메모리 시스템이 한번의 리프레시 사이클을 수행해주어야 데이터가 손실되지 않게 된다. 이것은 5% 가량의 컴퓨터 시간이 손실됨을 의미하며, DRAM을 사용함으로써 얻게되는 절약에 대한 작은 대가이다.
<여기에서 우리는 답을 찾아냅시다.>
전
(CBR;
before
) 리프레시 [그림 7-58 (b)]
: CBR 기법에서는
클럭이 0으로 내려가기 전에
클럭을 활성화시킨다.
그러면 DRAM은 외부 하드웨어 도움 없이 행 주소를 생성하고 그 행의 모든 셀을 리프레시 한다.
:
를 0으로 유지하고,
클럭을 사용하면 행 주소가 순서에 따라 내부적으로 생성되어 리프레시 한다.
자가 리프레시 (Self-refresh)
: 자가 리프레시는 CBR 리프레시와 동일하나,
와
가 최소 10㎲ 동안 0을 유지한다.
그러면 동일 칩 발진기가 자동적으로 리프레시 주소를 생성한다.
이 모드에서 나오면 완전히 리프레시 되는 것을 보장하기 위하여 버스트 리프레시를 수행하여야 한다.
리프레시 사이클의 분배
1. 버스트 리프레시 : 프로세서가 대기 상태로 들어가고 모든 행이 한번의 버스트로 리프레시 된다.
2. 분배 리프레시 : 전체 리프레시 주기에 걸쳐 리프레시 사이클을 분배할 수 있다. 대부분 이 기법 채택
3. 은닉 리프레시 : 정상적인 메모리 액세스 후
클럭을 0으로 유지하면 데이터가 출력 핀에 유지된다.
이제 DRAM이 내부적으로 행 주소를 증가시키므로, 몇 번이든지
클럭을 적용한다.
5. DRAM 제어기
PC/XT
: IBM PC와 XT는 개별 논리소자를 사용하여 DRAM을 8088 프로세서에 인터페이스 한다.
: 15㎲ 마다 시스템의 타이머에 의하여 시작하는
-only 분배 기법으로 리프레시 한다.
그러면 dummy 읽기 사이클이 DMA 제어기(8237)에 의하여 수행된다. (프로세서 시간의 5% 정도)
최신 컴퓨터
: PC/XT에서의 DMA 제어기, 시스템 타이머, 주소 디코딩 회로 등을 조합한 칩셋(chipset)으로 대체 되었다.
참고 도면
<부록> DRAM의 Refresh에 대한 검토
교재 332페이지 중간
리프레시(refresh). 저장 노드는 완벽하지 못하여 시간이 지나면 방전되는 것이 DRAM의 가장 큰 단점이라는 것을 잘 알고 있을 것이다. 이 때문에 리프레시 동작이 필요하게된다. 리프레시 동작이란 전하를 감지하여 증폭한 다음 다시 기록하는 것을 말한다. DRAM에 따라 차이는 있지만, 리프레시 작업은 각 메모리 셀에 대하여 1∼16 ms마다 한번씩 수행하여야 한다.
리프레시 작업은 생각하는 것보다 쉽게 구현할 수 있다. 그림 7.9를 보면 SRAM의 행이 엑세스될 때마다, 프리차지 회로가 캐패시터에 저장된 전하를 회복시킴을 알 수 있다. 따라서 단순히 메모리 내용을 읽거나 쓰기만 하여도 메모리가 리프레시 된다.
교재 391 페이지 아래
7.5.4 리프레시
7.1절에서 언급한 것처럼, 동적 RAM의 저장 셀은 캐패시터이다. 이 캐패시터는 결국 전하를 잃게 되므로, 각 셀의 전하는 주기적으로 다시 써야한다. 대개 이 작업은 15.625 ㎲ 마다 한번씩 행을 차례대로 엑세스함으로써 이루어진다. 그러므로 n비트의 행 주소를 가지고 있는 DRAM의 리프레시 주기(리프레시 없이 한 행이 버틸 수 있는 최대 시간)는,
리프레시 주기 = 2n x 15.625㎲ 이다.
예제 7.14
풀이 : 리프레시 주기는 32 ms이다
이 문제 풀이와 아래에 보인바와 같은 위 332 페이지의 설명의 상호 관계는 무엇일까요...
DRAM에 따라 차이는 있지만, 리프레시 작업은 각 메모리 셀에 대하여 1∼16 ms마다 한번씩 수행하여야 한다.
다른 교재를 참고하면 다음과 같습니다. \"인텔 마이크로프로세서\", Barry B. Brey저, 권갑현 공역
제4장 메모리 인터페이스
4-7 DRAM
◈ DRAM에 대한 재 고찰
4-1절에서 언급하였듯이 DRAM은 단지 2-4ms 정도 동안만 데이터를 유지하며, 주소 입력의 멀티플렉싱을 필요로 한다. 이미 4-1절에서 주소 멀티플렉싱에 관하여 살펴보았으므로, 여기서는 리프레시 동안 일어나는 DRAM의 동작에 관하여 자세히 살펴볼 것이다.
앞에서 언급하였듯이, DRAM은 짧은 주기 안에 자신의 전하를 잃어버리는 캐패시터 내에 데이터를 저장하기 때문에, 주기적으로 리프레시를 해주어야한다. DRAM을 리프레시 해주기 위해서는, 메모리 내의 내용이 주기적으로 읽혀지거나 써 넣어져야한다. 모든 읽기 또는 쓰기 동작은 자동적으로 DRAM의 전체를 리프레시 해준다. 리프레시 되는 비트의 수는 메모리 소자의 크기와 내부 조직에 따라 다르게 된다.
리프레시 사이클(refresh cycle)은 읽기, 쓰기, 혹은 데이터를 읽지도 쓰지도 하지 않는 특수한 리프레시 사이클에 의해 수행된다. 리프레시 사이클은 완전히 DRAM의 내부적인 동작이며, 시스템 내의 다른 메모리 소자들이 작동 중인 동안에 수행된다. 이와 같은 형태의 리프레시를 은닉 리프레시(hidden refresh), 투명 리프레시(transparent refresh) 혹은 사이클 훔치기(cycle stealing)라고 부른다.
<중략>
그림 4-39는
전용 리프레시 사이클을 위한 타이밍을 보여주고 있다.
와 쓰기 혹은 읽기 간의 주된 차이점은 이 사이클에서는 리프레시 주소만 인가된다는 점이다. 이 주소는 대개 7 비트 또는 8비트 2진 카운터에 의해 얻어진다. 카운터의 크기는 리프레시 되는 DRAM의 형태에 의해 결정된다. 리프레시 카운터는 각각의 리프레시 사이클의 끝에서 증가되며, 그 결과 모든 행들이 DRAM의 형태에 따라 2 또는 4ms만에 리프레시 된다.
256K x 1 DRAM에서처럼 4 ms 내에 256K 개의 행이 리프레시 되어야 한다면, 리프레시 사이클은 적어도 15.6 ㎲ 마다 한번씩 활성화 되어야한다. 예를 들어, 5 MHz 클럭으로 동작하는 8086/8088의 경우에는 읽기 또는 쓰기 동작에 800ns가 걸린다. DRAM이 매 15.6 ㎲ 마다 리프레시 사이클을 가져야 하므로, 매 19회의 메모리 읽기 또는 쓰기 동작마다 메모리 시스템이 한번의 리프레시 사이클을 수행해주어야 데이터가 손실되지 않게 된다. 이것은 5% 가량의 컴퓨터 시간이 손실됨을 의미하며, DRAM을 사용함으로써 얻게되는 절약에 대한 작은 대가이다.
<여기에서 우리는 답을 찾아냅시다.>
추천자료
 로터스사의 마케팅 전략
로터스사의 마케팅 전략- [C언어] C프로그래밍
- Intel 8051 microcontroller 의 구조적 측면에 대한 설명
- 무인 배달 트레이서
 컴퓨터 요소의 상호 연결 구조
컴퓨터 요소의 상호 연결 구조- [경영학] 삼성 반도체 성공전략
- PLC(programmable logic control)
- M-비지니스 무선인터넷
- 컴퓨터의 구성
- [IT와 경영정보시스템] '앨런 튜링기계'와 '폰 노이만'식 컴퓨터에 대한 상세한 레포트
 ARM GPIO & UART with C language
ARM GPIO & UART with C language- 왜 애플은 삼성전자를 버리지 못하는가 (적과의 동침)
- 유비쿼터스 환경에서의 it기술
- “INTEL”사의 회사탐색 (인텔)
- 가격2,300원
- 페이지수13페이지
- 등록일2002.11.03
- 저작시기2002.11
- 파일형식한글(hwp)
- 자료번호#210255

본 자료는 최근 2주간 다운받은 회원이 없습니다.



소개글