






























-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
해당 자료는 7페이지 까지만 미리보기를 제공합니다.
7페이지 이후부터 다운로드 후 확인할 수 있습니다.
7페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1장 연구과제 3번 (3점)
2장 연구과제 2번 (단, data는 담당교수 홈페이지 자료실의 타이태닉 데이터(titanic.csv)를 이용하시오.) 또한, 이 타이태닉 데이터에 나무모형을 적합하시오. 이러한 결과를 통해 로지스틱 회귀모형과 나무모형의 특징을 간단하게 비교해 보시오. (6점)
3장 연구과제 2번의 (1)~(3) (6점)
3장 연구과제 3번 (6점)
4장 연구과제 2번 (3점)
4장 연구과제 4번 (6점)
2장 연구과제 2번 (단, data는 담당교수 홈페이지 자료실의 타이태닉 데이터(titanic.csv)를 이용하시오.) 또한, 이 타이태닉 데이터에 나무모형을 적합하시오. 이러한 결과를 통해 로지스틱 회귀모형과 나무모형의 특징을 간단하게 비교해 보시오. (6점)
3장 연구과제 2번의 (1)~(3) (6점)
3장 연구과제 3번 (6점)
4장 연구과제 2번 (3점)
4장 연구과제 4번 (6점)
본문내용
데이터에 약간의 변화만 가해지더라도 나무구조가 변형될 수 있다. 이는 나무모형의 분할방법이 데이터에 크게 의존하고 있는 방법이기 때문이다.
지나치게 많은 노드와 가지를 가진 나무모형은 해석이 복잡해질 뿐만 아니라 새로운 자료에 적용시킬 때 예측오차가 매우 커지는 문제가 발생하는 경향이 있다. 따라서 적절한 크기의 나무모형을 선택하는 것은 해석력 뿐만 아니라 예측정확도를 향상시킬 수 있는 중요한 문제이다.
제4장 연구과제 4. 다음은 3개의 부트스트랩 데이터에 의해 생성된 3개의 분류기에 대한 예측결과이다. 분류기별 가중치는 괄호 안에 제시되어 있다. (6점)
관찰치 번호
목표변수
분류기 1 (0.2)
분류기 2 (0.6)
분류기 3 (0.2)
1
1
1
0
1
2
1
1
1
1
3
0
1
0
0
4
0
0
0
0
5
1
0
0
1
6
1
1
1
0
7
1
0
1
1
8
0
0
1
0
9
0
1
0
0
10
0
0
0
0
(1) 배깅의 투표방법에 의한 관찰치별 예측치는 무엇인가?
(2) 배깅 방법에 의한 오분류율을 계산하시오.
(3) 부스팅의 투표방법에 의한 각 관찰치별 예측치는 무엇인가?
(4) 부스팅 방법에 의한 오분류율을 계산하시오.
(1) 배깅의 투표방법에 의한 관찰치별 예측치는 무엇인가?
배깅(bagging) 방법은 브레이먼(Breiman, 1996)에 의해 개발된 분류앙상블 방법이다. 배깅은 bootstrap aggregating의 약어로, 훈련 데이터로부터 부트스트랩 데이터를 B번 생성하여 부트스트랩 데이터마다 분류기를 생성한 후 그 예측결과를 앙상블하는 방법이다. 배깅은 분류앙상블 방법 중에서 단순다수결 방식을 사용한다.
관찰치 번호
목표변수
분류기 1 (0.2)
분류기 2 (0.6)
분류기 3 (0.2)
예측치
1
1
1
0
1
1
2
1
1
1
1
1
3
0
1
0
0
0
4
0
0
0
0
0
5
1
0
0
1
0
6
1
1
1
0
1
7
1
0
1
1
1
8
0
0
1
0
0
9
0
1
0
0
0
10
0
0
0
0
0
(2) 배깅 방법에 의한 오분류율을 계산하시오.
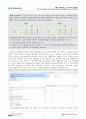
배깅(bagging) 방법에 의한다면 예측치는 단순다수결 방식에 의해서 결정된다. 단순다수결 방식에 의해 결정된 예측치를 목표변수와 비교해 보면 10차례의 관찰치에서 오분류가 일어난 사례는 1회이므로 오분류율은 1/10, 즉 10%(0.1)이다.
아래는 엑셀을 활용하여 오분류율을 검증한 화면이다.
(3) 부스팅의 투표방법에 의한 각 관찰치별 예측치는 무엇인가?
부스팅(boosting) 방법은 프로인트와 샤파이어(Freund and Schapire, 1997)에 의해 개발된 분류앙상블 방법이다. 부스팅은 배깅과 마찬가지로 B개의 분류기를 생성하여 종합하는 방법인데, 분류기를 생성하는 방식과 종합하는 방식이 조금 다르다.
부스팅에 사용되는 분류기는 오분류율을 랜덤으로 예측하는 것보다 조금이라도 좋은 예측모형이기만 하면 효고가 있다고 알려져 있다. 부스팅 방법의 개발자들은 이를 예측력이 약한 분류모형을 결합하여 강한 예측모형을 만드는 과정이라고 설명한다.
부스팅 방법을 실행하는 알고리즘 중에서 가장 많이 사용되는 것은 아다부스트(AdaBoost: adaptive boosting) 방법이다. 아다부스트 방법에는 분류기를 생성하는 방식에 따라 가중치를 반영한 분류기 생성방식과 표본추출에 의한 분류기 생성방식이 있다. 여기서는 가중치를 반영하는 방법을 이용하여 부스팅 투표방법에 의해 각 관찰치별 예측치를 알아본다.
각 분류기별로 오분류율을 계산하여 산출하고, 그 다음으로 각 분류기별 중요도를 산출한다. 그리고 나서 각 관측치 별 분류기 중요도를 가중치로 반영한 가중다수결 방식으로 분류한다. 예를 들어서 관찰치 번호 3은 분류기 1의 높은 가중치로 인하여 1로 예측될 수 있다.
분류기 구분
계산식
오분류율
분류기 1
0.2 (가중치) × 0.6 (정분류 수 × 0.1)
0.12
분류기 2
0.6 (가중치) × 0.7 (정분류 수 × 0.1)
0.42
분류기 3
0.2 (가중치) × 0.9 (정분류 수 × 0.1)
0.18
분류기 구분
계산식
중요도
분류기 1
1/2 × log {(1 - 0.12) / 0.12}
0.4326507131
분류기 2
1/2 × log {(1 - 0.42) / 0.42}
0.0700893516
분류기 3
1/2 × log {(1 - 0.18) / 0.18}
0.3292706736
아래의 [표 4-4]는 부스팅 방법에 의한 예측치를 산출한 결과이다.
관찰치 번호
목표변수
분류기 1 (0.2)
분류기 2 (0.6)
분류기 3 (0.2)
예측치
1
1
1
0
1
1
2
1
1
1
1
1
3
0
1
0
0
1
4
0
0
0
0
0
5
1
0
0
1
0
6
1
1
1
0
1
7
1
0
1
1
0
8
0
0
1
0
0
9
0
1
0
0
1
10
0
0
0
0
0
(4) 부스팅 방법에 의한 오분류율을 계산하시오.
부스팅(boosting) 방법에 의한다면 예측치는 가중다수결 방식에 의해서 결정된다. 가중다수결 방식에 의해 결정된 예측치를 목표변수와 비교해 보면 10차례의 관찰치에서 오분류가 일어난 사례는 4회이므로 오분류율은 4/10, 즉 40%(0.4)이다.
아래는 엑셀을 활용하여 오분류율을 검증한 화면이다.
<참고문헌>
김성수, 김현중, 정성석, 이용구, 「R을 이용한 다변량분석」, 한국방송통신대학교 출판문화원, 2015.
장영재, 김현중, 조형준, 「데이터마이닝」, 한국방송통신대학교 출판문화원, 2016.
https://analysis-flood.tistory.com/43?category=725389 42. 데이터마이닝-분류분석
https://analysis-flood.tistory.com/44?category=725389 43. 데이터마이닝-분류분석2
https://analysis-flood.tistory.com/45?category=725389 44. 데이터마이닝-분류분석3
https://www.quora.com/Why-decision-trees-are-called-unstable-models Why decision trees are unstable models?
지나치게 많은 노드와 가지를 가진 나무모형은 해석이 복잡해질 뿐만 아니라 새로운 자료에 적용시킬 때 예측오차가 매우 커지는 문제가 발생하는 경향이 있다. 따라서 적절한 크기의 나무모형을 선택하는 것은 해석력 뿐만 아니라 예측정확도를 향상시킬 수 있는 중요한 문제이다.
제4장 연구과제 4. 다음은 3개의 부트스트랩 데이터에 의해 생성된 3개의 분류기에 대한 예측결과이다. 분류기별 가중치는 괄호 안에 제시되어 있다. (6점)
관찰치 번호
목표변수
분류기 1 (0.2)
분류기 2 (0.6)
분류기 3 (0.2)
1
1
1
0
1
2
1
1
1
1
3
0
1
0
0
4
0
0
0
0
5
1
0
0
1
6
1
1
1
0
7
1
0
1
1
8
0
0
1
0
9
0
1
0
0
10
0
0
0
0
(1) 배깅의 투표방법에 의한 관찰치별 예측치는 무엇인가?
(2) 배깅 방법에 의한 오분류율을 계산하시오.
(3) 부스팅의 투표방법에 의한 각 관찰치별 예측치는 무엇인가?
(4) 부스팅 방법에 의한 오분류율을 계산하시오.
(1) 배깅의 투표방법에 의한 관찰치별 예측치는 무엇인가?
배깅(bagging) 방법은 브레이먼(Breiman, 1996)에 의해 개발된 분류앙상블 방법이다. 배깅은 bootstrap aggregating의 약어로, 훈련 데이터로부터 부트스트랩 데이터를 B번 생성하여 부트스트랩 데이터마다 분류기를 생성한 후 그 예측결과를 앙상블하는 방법이다. 배깅은 분류앙상블 방법 중에서 단순다수결 방식을 사용한다.
관찰치 번호
목표변수
분류기 1 (0.2)
분류기 2 (0.6)
분류기 3 (0.2)
예측치
1
1
1
0
1
1
2
1
1
1
1
1
3
0
1
0
0
0
4
0
0
0
0
0
5
1
0
0
1
0
6
1
1
1
0
1
7
1
0
1
1
1
8
0
0
1
0
0
9
0
1
0
0
0
10
0
0
0
0
0
(2) 배깅 방법에 의한 오분류율을 계산하시오.
배깅(bagging) 방법에 의한다면 예측치는 단순다수결 방식에 의해서 결정된다. 단순다수결 방식에 의해 결정된 예측치를 목표변수와 비교해 보면 10차례의 관찰치에서 오분류가 일어난 사례는 1회이므로 오분류율은 1/10, 즉 10%(0.1)이다.
아래는 엑셀을 활용하여 오분류율을 검증한 화면이다.
(3) 부스팅의 투표방법에 의한 각 관찰치별 예측치는 무엇인가?
부스팅(boosting) 방법은 프로인트와 샤파이어(Freund and Schapire, 1997)에 의해 개발된 분류앙상블 방법이다. 부스팅은 배깅과 마찬가지로 B개의 분류기를 생성하여 종합하는 방법인데, 분류기를 생성하는 방식과 종합하는 방식이 조금 다르다.
부스팅에 사용되는 분류기는 오분류율을 랜덤으로 예측하는 것보다 조금이라도 좋은 예측모형이기만 하면 효고가 있다고 알려져 있다. 부스팅 방법의 개발자들은 이를 예측력이 약한 분류모형을 결합하여 강한 예측모형을 만드는 과정이라고 설명한다.
부스팅 방법을 실행하는 알고리즘 중에서 가장 많이 사용되는 것은 아다부스트(AdaBoost: adaptive boosting) 방법이다. 아다부스트 방법에는 분류기를 생성하는 방식에 따라 가중치를 반영한 분류기 생성방식과 표본추출에 의한 분류기 생성방식이 있다. 여기서는 가중치를 반영하는 방법을 이용하여 부스팅 투표방법에 의해 각 관찰치별 예측치를 알아본다.
각 분류기별로 오분류율을 계산하여 산출하고, 그 다음으로 각 분류기별 중요도를 산출한다. 그리고 나서 각 관측치 별 분류기 중요도를 가중치로 반영한 가중다수결 방식으로 분류한다. 예를 들어서 관찰치 번호 3은 분류기 1의 높은 가중치로 인하여 1로 예측될 수 있다.
분류기 구분
계산식
오분류율
분류기 1
0.2 (가중치) × 0.6 (정분류 수 × 0.1)
0.12
분류기 2
0.6 (가중치) × 0.7 (정분류 수 × 0.1)
0.42
분류기 3
0.2 (가중치) × 0.9 (정분류 수 × 0.1)
0.18
분류기 구분
계산식
중요도
분류기 1
1/2 × log {(1 - 0.12) / 0.12}
0.4326507131
분류기 2
1/2 × log {(1 - 0.42) / 0.42}
0.0700893516
분류기 3
1/2 × log {(1 - 0.18) / 0.18}
0.3292706736
아래의 [표 4-4]는 부스팅 방법에 의한 예측치를 산출한 결과이다.
관찰치 번호
목표변수
분류기 1 (0.2)
분류기 2 (0.6)
분류기 3 (0.2)
예측치
1
1
1
0
1
1
2
1
1
1
1
1
3
0
1
0
0
1
4
0
0
0
0
0
5
1
0
0
1
0
6
1
1
1
0
1
7
1
0
1
1
0
8
0
0
1
0
0
9
0
1
0
0
1
10
0
0
0
0
0
(4) 부스팅 방법에 의한 오분류율을 계산하시오.
부스팅(boosting) 방법에 의한다면 예측치는 가중다수결 방식에 의해서 결정된다. 가중다수결 방식에 의해 결정된 예측치를 목표변수와 비교해 보면 10차례의 관찰치에서 오분류가 일어난 사례는 4회이므로 오분류율은 4/10, 즉 40%(0.4)이다.
아래는 엑셀을 활용하여 오분류율을 검증한 화면이다.
<참고문헌>
김성수, 김현중, 정성석, 이용구, 「R을 이용한 다변량분석」, 한국방송통신대학교 출판문화원, 2015.
장영재, 김현중, 조형준, 「데이터마이닝」, 한국방송통신대학교 출판문화원, 2016.
https://analysis-flood.tistory.com/43?category=725389 42. 데이터마이닝-분류분석
https://analysis-flood.tistory.com/44?category=725389 43. 데이터마이닝-분류분석2
https://analysis-flood.tistory.com/45?category=725389 44. 데이터마이닝-분류분석3
https://www.quora.com/Why-decision-trees-are-called-unstable-models Why decision trees are unstable models?
추천자료
 한국방송통신대학(방통대) 평생교육원의 연혁, 한국방송통신대학(방통대) 평생교육원의 교육...
한국방송통신대학(방통대) 평생교육원의 연혁, 한국방송통신대학(방통대) 평생교육원의 교육...- 한국방송통신대학(방통대) 평생교육원의 설립취지, 한국방송통신대학(방통대) 평생교육원의 ...
- [방송통신대학교 정보통계학과] 2015년 1학기 엑셀데이터분석 출석대체 과제물
- (30점 만점) 한국방송통신대학교 정보통계학과 엑셀데이터분석 출석수업대체 실험실습과제
- (30점 만점) 한국방송통신대학교 정보통계학과 통계조사방법론 중간과제
- (30점 만점) 한국방송통신대학교 정보통계학과 통계패키지 출석수업대체 실험실습과제
- (30점 만점) 한국방송통신대학교 정보통계학과 통계학개론 출석수업대체 실험실습과제
- (30점만점)한국방송통신대학교 정보통계학과 데이터처리와활용 중간과제물
- (30점만점)한국방송통신대학교 정보통계학과 R컴퓨팅 출석수업대체시험 실습과제
- (30점 만점) 한국방송통신대학교 다변량분석 출석수업대체과제
- 가격6,000원
- 페이지수21페이지
- 등록일2020.03.26
- 저작시기2019.11
- 파일형식한글(hwp)
- 자료번호#1127783


- 편집

- 내용
- 가격



소개글